Technological advancements such as IoT, robotic-assisted surgeries, Artificial Intelligence (AI), Machine Learning (ML), and algorithms based on clinical data highlight the giant step taken in recent years for modernizing the healthcare industry. With the state of medical services and research advancement still evolving, data has become the foundation to a tech-driven future for the industry. Synthetic data can play a pivotal role for the advancements in healthcare.
The global synthetic data generation market is expected to grow from USD 0.3 billion in 2023 to USD 2.1 billion by 2028, with a CAGR of 45.7% [1]. With the global healthcare analytics market expected to reach over USD 121.1 billion by 2030 [2], data required for innovation will only become more valuable and synthetic data generation is an area of healthcare innovation that can become a potential gamechanger. This article will shed some light on what synthetic data is and how it can help the healthcare industry.
Generative Adversarial Networks (GANs)
To understand synthetic data, it is also important to understand how they are synthesized. GANs refer to a class of deep-learning models that generate synthetic clinical data. Developed by Goodfellow and his colleagues in 2014 [3], GANs consist of two machine learning algorithms—the generator and the discriminator. To put it simply, the generator keeps generating data while the discriminator attempts to differentiate such data from real data. Over the course of this cycle, the generator gradually learns to create data close to real-world counterparts, eventually generating data that the discriminator cannot differentiate at least 50% of the time, which would put the discriminator’s filtering attempts on par with guesswork [4].
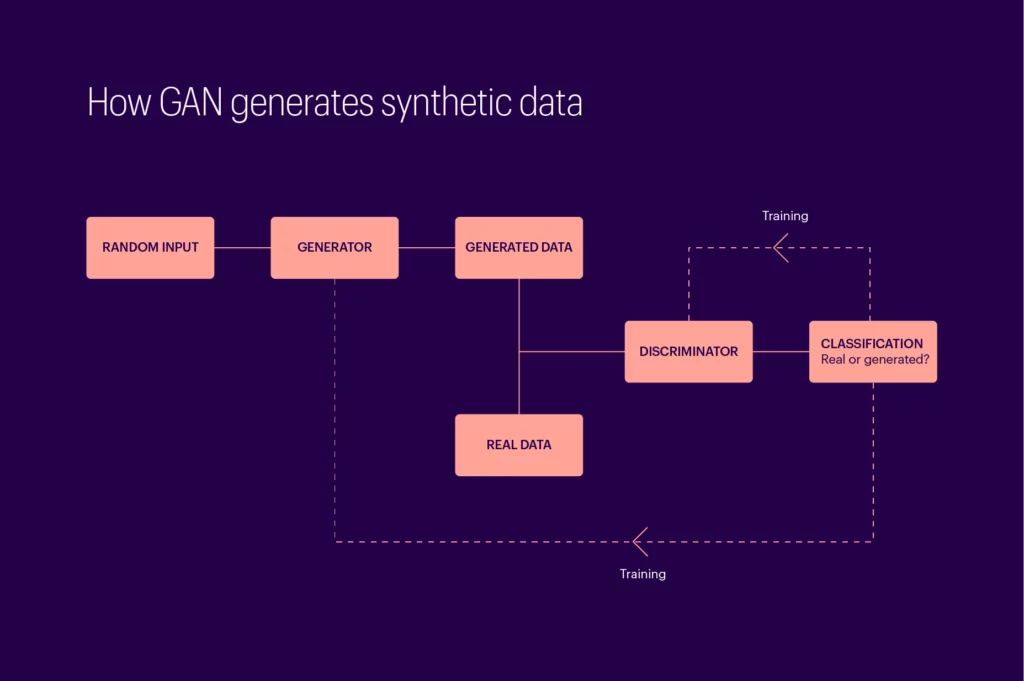
Imaged above: How GAN generates synthetic data.
How synthetic data can empower the healthcare industry
While GANs have come a long way, what data to synthesize for the healthcare industry and how to ensure applicability is a relatively contended and newer point of discussion. While we cannot measure the effectiveness and feasibility of using synthetic data practically yet, we can explore the potential it holds for bringing sweeping changes to the healthcare industry.
1. Enhancing AI/ML for healthcare:
The biggest potential benefit of synthetic data for the healthcare industry is in empowering AI innovation. Analysts, developers, researchers, and data scientists all require enormous amounts of real-world data to train AI algorithms. This need often involves Personally Identifiable Information (PII) and Protected Health Information (PHI), which patients and institutions may not want to share due to privacy or security concerns.
Data augmentation is the inclusion of modified copies of data to increase the amount of data available for an algorithm to be trained on. This falls perfectly within the focus of synthetic data and can solve issues of privacy concerns in training data. The synthesized data is not only usable but can be shared with third party vendors and researchers without the need for concerns from any involved parties. A health insurance company based in the US built a data exchange platform using synthetic data, which has resulted in more than eight products developed by third-party vendors while not compromising patient data on any level [5]. Finally, minority demographics are often subject to biases while training ML algorithms [6] as their datasets would be far less represented. Augmenting the data available for these groups can prove crucial in making AI/ML better in general, as well as for underrepresented datasets.
2. Privacy protection for patients:
With individual privacy being a concern today, there are growing concerns surrounding PII in healthcare. Synthetic data can facilitate anonymization of PII as it only references real data while generating fully synthetic information. In successfully synthesized data, no single data point is attributable to any individual patient, but the overall patterns within the dataset can be maintained. As the data does not relate to a natural person, synthesized medical data is neither sensitive nor confidential [4]. This also means that researchers and medical personnel don’t have to spend time and effort in obtaining consent for collecting and using patient data.
3. Clinical research and development:
In research, Generative AI enables the creation of synthetic data to increase the size of datasets for focused research. This is a crucial stage while training machine learning algorithms since the success of such an algorithm is a function of the sample size of the input data. Hence, where datasets are imbalanced and not representative of the population they aim to serve, Generative AI—in the form of synthetic minority oversampling technique (SMOTE)—can be used to selectively augment the representation of minority data points [4]. This data can also be used to improve the reproducibility of research because synthetic datasets can readily be shared with other researchers or third parties to verify models and analysis strategies.
4. Digital twins:
GANs can be used to construct synthetic digital twins where an artificial system preserves all the patterns of the true system while providing a copy that can be used for testing and experimentation. For clinical data, as the digital twin preserves the relationships, patterns, and characteristics of the original data, it can used for data analysis, accelerating data acquisition, and labeling. Personalized digital twins are being used to monitor nutrition and weight, as well as sudden health changes [7].
5. Medical education:
Generative AI can also be used to rapidly produce training material and simulations for students to use for learning. Such training material is customizable; for example, if a student is having difficulty distinguishing between a left lower lobe collapse and consolidation, examples of each type could be created and presented in the form of X-rays to the student [4]. In this way, synthetic data can assist in ‘edge-case’ learning material and reduce the proportion of material presented that the student is already comfortable with. Also, since each image can be created to be unique, they cannot be reverse searched during examinations and can also differ from examples that students may have shown in lectures and during revisions [4]. It is regarded that low-fidelity data can be useful for educational purposes (e.g., methodological and software education) and initial data exploration, whereas high-fidelity data are more useful for developing models [8].
Concerns and conclusion
While generated data can help in providing additional data to balance models, overcorrection of imbalances can also worsen model performance by leading to poor calibration of risk predictions or wrong absolute risks [8]. Even if corrections and balancing were done perfectly, another area of concern is whether synthetic data would ever be used for decision-making or whether final analyses will always need to be conducted on the original data [8]. Generating synthetic data is a highly resource-intensive process, especially for complex images found in the medical context. Despite recent advances, generating data remains computationally intensive, and it can take weeks to develop successful models [4]. Additional research is needed to understand whether potential benefits outweigh the time and effort required to generate synthetic data that are fit for use [8]. Finally, there is no clear legislation surrounding the use of synthetic data [9] as of now, which can lead to questions on how and to which extent synthetic data would be regulated or otherwise.
Despite its unpolished state, synthetic data promises to be a potential game-changer for how medical records and data are procured, used, and analyzed. Much of the interest and speculation comes because of how vital data and its handling have become for the healthcare industry. Healthcare innovations such as telehealth, retail healthcare, and asynchronous consultations will also come with their own data-related problems and requirements. Whether it can prove its skeptics wrong and become a mainstay of healthcare data, however, is something only time can tell.
Synthetic Data is just a part of what Generative AI can do for your business. Reach out to us to know more about Generative AI and how to make your business future-ready.
Bibliography
1. “Global Synthetic Data Generation Market Report 2023: Increasing Need for Data Privacy and Compliance Fuels the Sector.” PR Newswire: press release distribution, targeting, monitoring and marketing, June 13, 2023. https://www.prnewswire.com/news-releases/global-synthetic-data-generation-market-report-2023-increasing-need-for-data-privacy-and-compliance-fuels-the-sector-301848528.html.
2. “Healthcare Analytics Market (by Component: Software, Services, and Hardware; by Type: Descriptive, Predictive, and Prescriptive; by Application: Clinical, Financial, and Operational & Administrative; by Delivery Mode: Web Hosted, Cloud-Based, and on-Premises, and by End User: Life Science, Healthcare Payers, and Healthcare Providers) – Global Industry Analysis, Size, Share, Growth, Trends, Regional Outlook, and Forecast 2022 – 2030.” Precedence Research, April 2023. https://www.precedenceresearch.com/healthcare-analytics-market#.
4. Arora, Anmol, and Ananya Arora. “Generative Adversarial Networks and Synthetic Patient Data: Current Challenges and Future Perspectives.” Future healthcare journal, July 2022. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9345230/
5. “Guide: How to Leverage AI-Powered Synthetic Data in Enterprises.” MOSTLY AI, 2023. https://mostly.ai/ebook/synthetic-data-for-enterprises
6. Rajotte, Jean-Francois, Robert Bergen, David L Buckeridge, Khaled El Emam, Raymond Ng, and Elissa Strome. “Synthetic Data as an Enabler for Machine Learning Applications in Medicine.” iScience, October 13, 2022. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9619172/
7. Pool, Rebecca. “Human Digital Twins Are Set to Revolutionize Medicine.” EE Times Europe, April 18, 2023. https://www.eetimes.eu/human-digital-twins-are-set-to-revolutionize-medicine/
8. Kokosi, Theodora, and Katie Harron. “Synthetic Data in Medical Research.” BMJ Medicine, September 1, 2022. https://bmjmedicine.bmj.com/content/1/1/e000167
9. Arora, Anmol, and Ananya Arora. “Synthetic Patient Data in Health Care: A Widening Legal Loophole.” The Lancet, March 28, 2022. https://www.thelancet.com/journals/lancet/article/PIIS0140-6736(22)00232-X/fulltext


