Understanding MLOps
Machine learning operations (MLOps) are often defined as using ML models in development/operations (DevOps) scenarios. But a more nuanced – yet simple – way of approaching this definition is to look at MLOps as everything that surrounds machine learning. This includes data engineering, DevOps infrastructure systems, experiment management, as well as monitoring and observability for data and data pipelines across a wide range of projects, processes, and use cases.
A machine learning model aims to create a statistical model with the data collected by applying an algorithm. Therefore, data, ML models, and code are the pillars of any ML-based software. The process starts with collecting and preparing the data to be analyzed, after which the machine learning algorithm is written and executed. Finally, after training the model, it is deployed as a part of business applications. The image below depicts the functions of a general MLOps model.
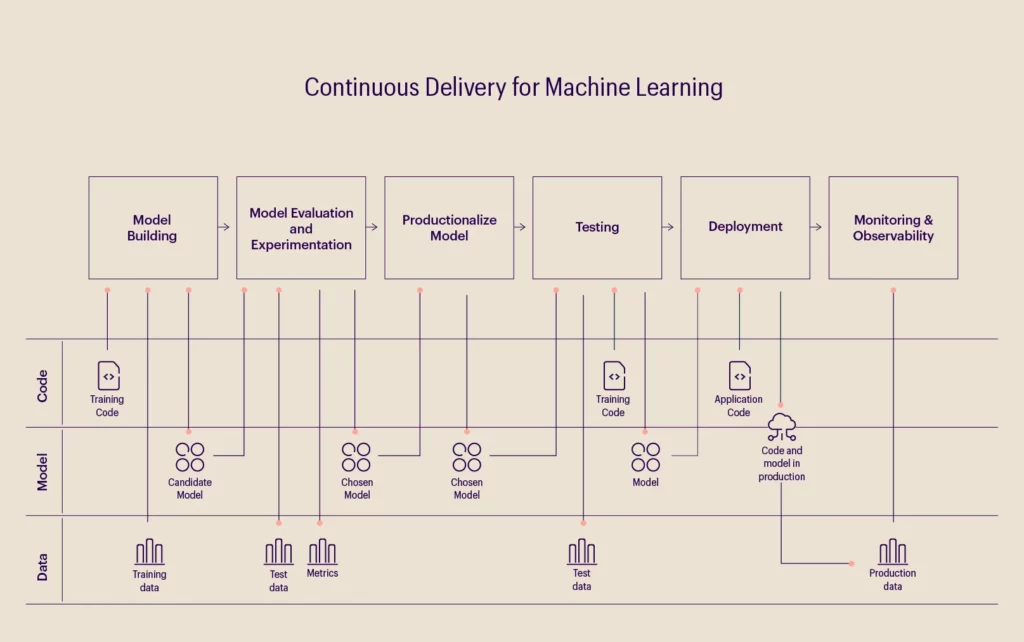
Machine learning is currently being used to great effect across industries, including retail, technology, and supply chain, where innovation in pattern detection, risk analysis, and recommendation systems are a few significant use cases. However, these have also been accompanied by data-related issues such as transparency, regulatory compliance, ethics, privacy, and developer/data bias.
Enter MLOps, where tools can automatically record and store information about how data is used, when models are deployed and recalibrated, by whom, and why changes were made, thus establishing transparency.
MLOps: Revolutionizing the healthcare industry
In the healthcare industry, where the Health Insurance Portability and Accountability Act of 1996 (HIPAA) and the Payment Card Industry (PCI) add more layers of complexity to patient privacy and regulatory compliance, development and deployment teams can work with a robust MLOps framework to adhere to compliance protocols and privacy regulations, while also leveraging data for numerous applications.
Let’s look at a specific use case within the healthcare industry – wound care in post-acute treatments, which is often overshadowed by other common illnesses such as heart conditions, strokes, etc. As a lack of data in the post-acute space – compared to acute hospital and ambulatory care – persists, data capturing is often limited to standardized intake forms. Apart from lacking a structured care delivery model, this space also relies heavily on vendor/third-party relationships for intervention decisions, which are crippled by outdated and highly subjective wound care quality metrics.
A niche electronic health record (EHR) system would be the first step to resolving this challenge and creating advanced insight generation capabilities for the post-acute space. This system can leverage decades of unique experience to ensure that environmental context is considered. Specific attributes that change routinely between evaluations should also be grouped together within this system to increase the accuracy of data capture in keeping with the clinical workflow. Patient-specific attributes should then be captured at the initial consultation and updated during the treatment, where applicable. The following are some functionalities that an EHR system provides:
- Homogeneity: Clinicians use the same EHR systems to maintain and analyze data.
- Auto-calculation: The initial entry data in the appropriate fields is auto-calculated through an AI algorithm, which prevents incremental error generation.
- Consistency: Mandated entries of wound factors, which are necessary in wound evaluation, can ensure consistency in data entry.
- Data accuracy: A seamless UI/UX interface reduces erroneous data entry and helps maintain data accuracy.
Leveraging MLOps to simplify post-acute wound care.
The following image outlines the MLOps model that would streamline this process for the post-acute space.
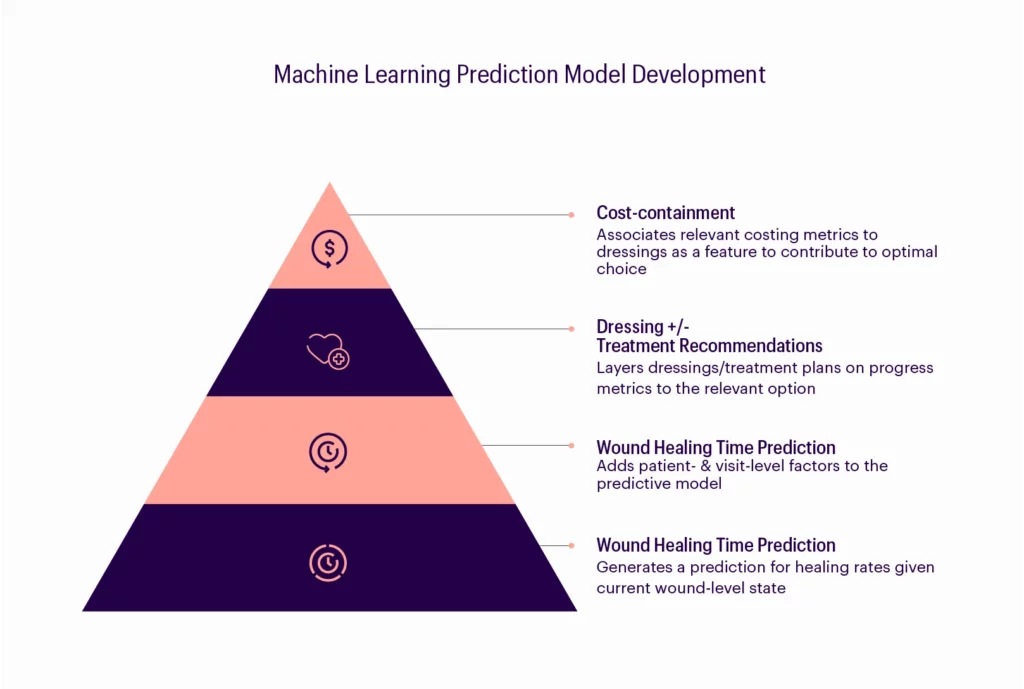
- Develop a machine learning model (predicts wound healing time) that is robust and dynamic while still maintaining a level of generality across defined categories of wound-level factors.
- Integrate patient- and visit-level factors into the model as they significantly influence the independent variable across the defined wound-level categories.
- Add the complete machine learning model – after monitoring, adjusting, and validating it – using live EHR data without re-integrating the results into the EHR until appropriate efficacy is confirmed. The model will then predict wound healing time to create a more accurate predictive tool.
- Use the wound healing time model to produce a dynamic and predictive healing trajectory.
- Concurrently develop a “progress” metric representing weighted wound-level variables that contribute to measuring and determining change over time, thus defining a solid metric for “outcome”.
- Measure the effect and intervention of treatment by tracking the progress and noting the variables that change over time. This will determine the optimal treatment plan given any constellation of wound-level factors (i.e., wound type, severity, anatomic location), patient-level factors (i.e., comorbidities, medication), and visit-level factors (i.e., BMI determinations, lab results.) Then, introduce a production pilot once acceptable efficacy is established through monitoring, analysis, and adjustment.
- Attach cost variables to the dressings and interventions used so that the EHR can determine clinical outcomes and cost-effectiveness concurrently. It can also include a hybrid of these factors for a data-driven treatment recommendation engine that augments physician decision-making.
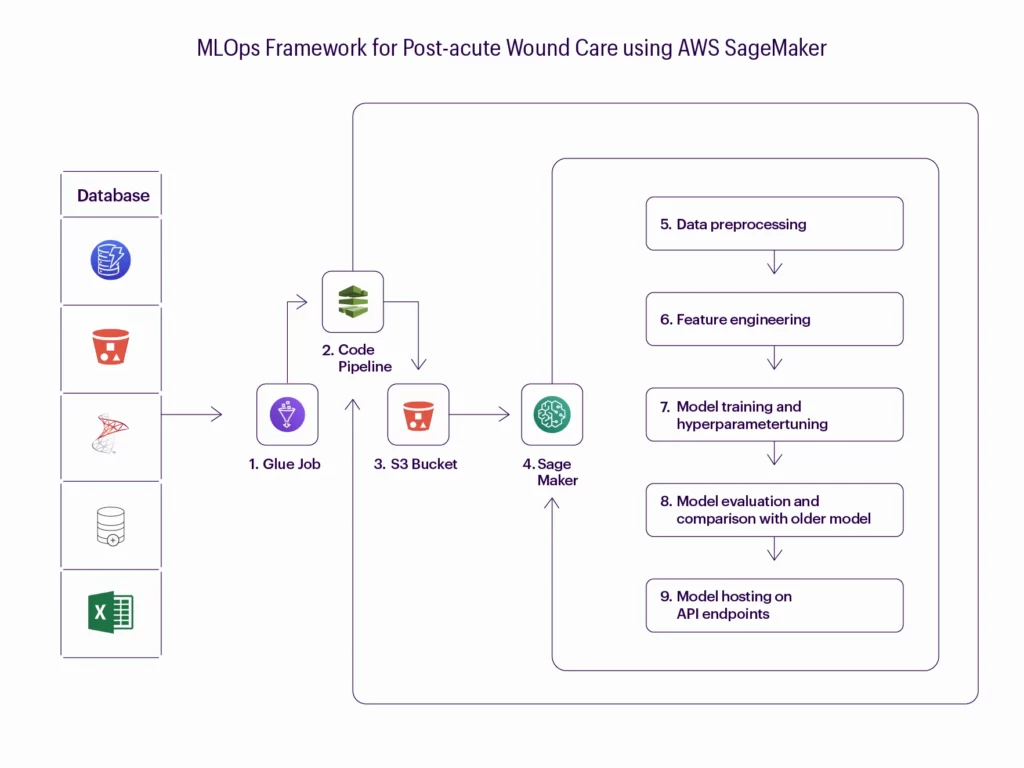
Streamlining patient outcomes: An MLOps framework for healthcare.
This model building pipeline provides an end-to-end architecture from ETL, to develop and deploy the machine learning model in the AWS environment. The model building pipeline helps achieve the following:
- Version your data effectively and kick off a new model training run.
- Validate the received data and check against data drift.
- Efficiently preprocess data for your model training and validation.
- Effectively train your machine learning models.
- Track your model training.
- Analyze and validate your trained and tuned models.
- Deploy the validated model.
- Scale the deployed model.
- Capture new training data and model performance metrics with feedback loops.
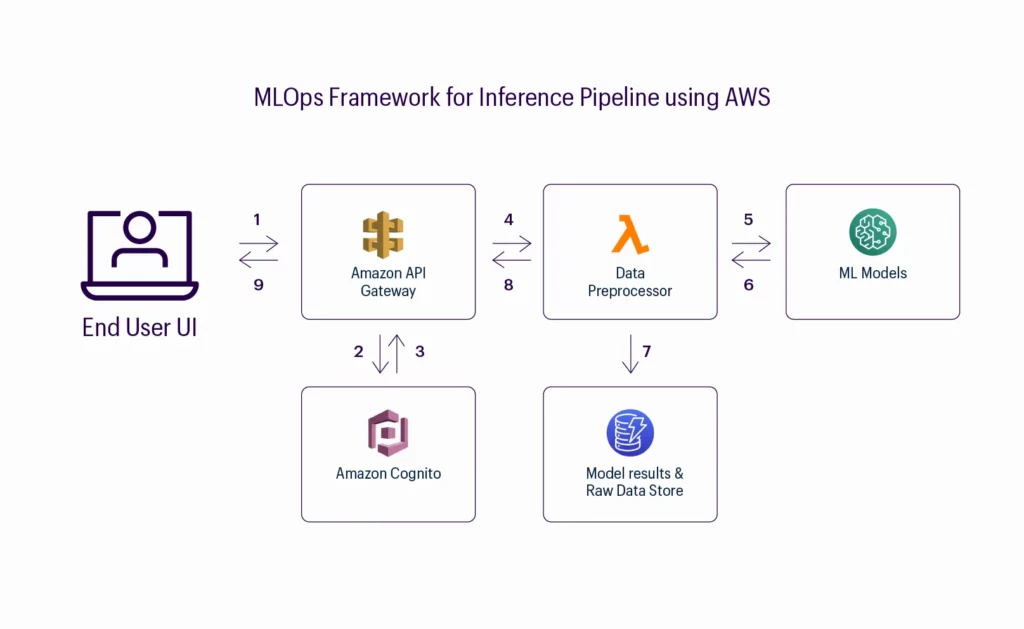
This inference pipeline model provides an architecture for receiving data elements passed from front-end EHR through the AWS API Gateway. The inference building pipeline helps achieve the following:
- Process data obtained and feed it to the ML model hosted on the API endpoint.
- Deploy and train the model to perform inference.
- Test the model’s performance and use it to make predictions on new data points.
It must be noted here that deploying inference services is still a relatively new discipline, with its own unique set of challenges. These include incorporating changing data patterns, identifying patterns, deploying necessary changes, re-architecting to fit structured databases, and so on.
Challenges and recommendations: How to make the most of MLOps.
However, a few architectural patterns are now being put into practice to address these challenges, and many of them are attempting to abstract the mechanics of production from data science teams’ practices. In my opinion, to solve these problems, the following can be possible solutions:
- Creating a cross-functional team of data scientists and data engineers.
- Using production-ready platforms right from the start of the project.
- Monitoring solutions with optimization techniques to understand performance anomalies in ML.
- Adopting higher-level automation and abstractions wherever possible.
References
1. “ML-Ops.Org.” ML Ops: Machine Learning Operations. Accessed June 1, 2022. https://ml-ops.org/content/mlops-principles.
2. “The State of Mlops in 2021.” ZDNET. Accessed January 20, 2022. https://www.zdnet.com/article/the-state-of-mlops-in-2021/.


