As organizations evolve, data migration can become essential to modernizing data infrastructure, enhancing scalability, and unlocking business insights through advanced analytics. Data migration scenarios can range from shifting on-premises databases to the cloud, moving between cloud providers, or transitioning from one service to another within the same cloud platform. These migrations provide a wealth of business value but come with significant complexity, requiring careful planning, robust strategies, and often automation to ensure success.
The common drivers for data migration include:
- Infrastructure Modernization: Legacy systems often lack the agility and scalability of cloud solutions, prompting organizations to migrate data to more versatile environments.
- Operational Efficiency: Migrating data to centralized or optimized platforms reduces overhead, simplifies maintenance, and enables quicker responses to business needs.
- Enhanced Data Access and Integration: Cloud-based and modern storage solutions allow easier integration of data across departments, applications, and even geographies, improving access to insights and data-driven decision-making.
- Compliance and Security Enhancements: Migrating to secure cloud platforms or advanced data management services enables organizations to meet stringent compliance requirements and improve data protection.
- Cost Optimization: Efficiently managed cloud resources, with pay-as-you-go models, can reduce infrastructure costs compared to the capital-intensive setup and maintenance of on-premises solutions.
By aligning data migration needs with strategic objectives and leveraging automation, businesses can turn the challenges of data migration into opportunities for enhanced innovation, agility, and cost savings.
Dive deep into key considerations, strategies, and best practices for executing data migrations, whether migrating from on-premises to the cloud, moving between cloud platforms, or upgrading within the same cloud environment.
Inherent Complexities in Data Migration
- Data Volume and Variety: Modern organizations deal with vast amounts of structured, semi-structured, and unstructured data. Migrating high volumes of diverse data types can be challenging, especially when legacy formats require transformation to fit modern architectures.
- Downtime and Business Continuity: Many migrations involve mission-critical systems, where downtime or data inconsistencies could disrupt operations. Ensuring continuity and minimizing downtime during migration is often a top priority.
- Compatibility and Interoperability: Data platforms differ in structure, schema, and functionality, requiring extensive planning and often reconfiguration of applications and databases to work in the target environment.
- Data Quality and Integrity: Data corruption, inconsistencies, or loss during migration can have significant business impacts. Maintaining high data quality and performing rigorous validation are essential for migration success.
- Security and Compliance: Migrating sensitive data introduces risks, especially when moving between environments with different security protocols. Ensuring compliance with standards such as GDPR, HIPAA, and SOC 2, among others, adds to the complexity.
- Cost Management: Migration projects can be resource-intensive, and unexpected costs may arise from extended timelines, additional storage needs, or performance inefficiencies. Planning for cost management and tracking migration expenses is critical.
Key Considerations for Performing Data Migrations
For successful data migrations, it’s critical to follow a structured approach across the assessment, planning, and execution phases. Each phase comes with unique considerations that help address potential challenges and align the migration with organizational goals.
Assessment Phase
In the assessment phase, the goal is to thoroughly evaluate the existing environment, data architecture, and business requirements to set a strong foundation for the migration process. The key considerations during the assessment phase include:
1. Current environment analysis:
- Inventory all data sources, storage systems, and applications.
- Identify dependencies, interconnections, and the nature of data (structured, unstructured, semi-structured) to understand complexity and compatibility with the target system.
2. Data Quality and Integrity:
- Assess data quality to identify inconsistencies, duplicates, or outdated records.
- Identify cleansing requirements that could simplify or optimize the migration, especially for legacy data.
3. Performance and Scalability Requirements:
- Analyze current performance levels to set benchmarks for the target environment.
- Estimate future growth to ensure the target system can handle increasing volumes and data complexity.
4. Security and Compliance:
- Identify any compliance requirements (e.g., GDPR, HIPAA) or regulatory standards.
- Define access control policies, encryption requirements, and other security protocols.
5. Cost and ROI Analysis:
- Evaluate the cost-effectiveness of different migration approaches.
- Assess potential savings, benefits, and ROI to justify the migration investment.
Planning Phase
The planning phase involves designing the migration strategy and developing a roadmap, ensuring that all resources, tools, and processes are aligned to meet the data migration objectives. The key considerations during the planning phase include:
1. Migration Strategy:
- Determine the migration approach (e.g., lift-and-shift, re-platforming, refactoring) based on the assessment phase findings.
- Decide on a phased migration or big-bang approach based on system criticality and business needs.
2. Data Mapping and Transformation:
- Define data mappings between the source and target systems to maintain schema and data integrity.
- Identify transformation requirements to ensure data fits the target system’s format and structure, especially if migrating to a different database or data model.
3. Tools and Automation:
- Select migration tools and automation platforms to streamline tasks like ETL, data validation, and monitoring.
- Use Infrastructure-as-Code (IaC) to consistently provision resources, especially in cloud environments.
4. Testing and Validation Plan:
- Develop a comprehensive testing strategy covering data integrity, application functionality, performance, and security.
- Include automated testing where possible for regression, data consistency, and compliance checks.
5. Risk Management and Contingency Planning:
- Identify potential risks (e.g., data loss, downtime, security risks) and outline contingency plans.
- Develop rollback procedures in case of issues during migration execution.
6. Stakeholder Communication:
- Define communication protocols and responsibilities for each team involved.
- Schedule regular updates and checkpoints with stakeholders to align on progress and address potential issues early.
Execution Phase
The execution phase involves the actual migration process, where data is transferred, transformed, and validated in the target environment. The key considerations during the execution phase include:
1. Data Extraction, Transformation, and Loading:
- Execute ETL/ELT processes with careful attention to data extraction from source systems, transformations as per mapping definitions, and loading to the target system.
- For high data volumes, leverage tools that support incremental loading and parallel processing to optimize performance.
2. Incremental Migration and Synchronization:
- Use incremental or dual-write approaches to ensure data consistency, especially for ongoing changes in the source system.
- Implement synchronization schedules or real-time replication, if needed, to prevent data mismatches.
3. Data Validation and Testing:
- Validate the accuracy and completeness of migrated data, comparing source and target records using automated data validation scripts.
- Conduct application testing to ensure that application functionalities perform as expected in the new environment.
4. Security and Access Management:
- Verify that access controls, data encryption, and security protocols are correctly implemented and aligned with the planned security framework.
- Conduct security audits to detect any vulnerabilities introduced during migration.
5. Go-Live and Post-Migration Validation:
- Plan and conduct a controlled go-live with all stakeholders, ensuring a smooth transition to the target environment.
- Keep rollback plans ready for unforeseen issues and have the team prepared to execute them if needed.
- Perform a post-migration review to evaluate data integrity, system performance, and any remaining discrepancies.
MathCo’s Strategies for Data Migrations
Use Case 1
Background
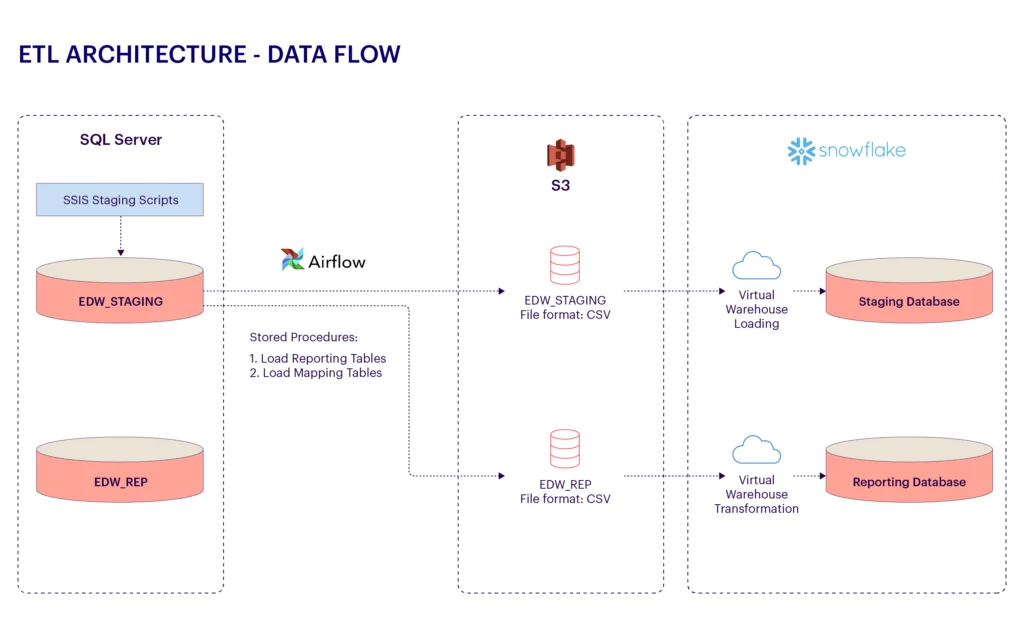
A US-based admissions management and automated enrolment marketing solution and services provider with an extensive data infrastructure on SQL Server sought to modernize its data platform. As the volume of data grew from transactional systems, website analytics, and customer interactions, the organization faced scalability issues, high operational costs, and challenges in performing advanced analytics on-premises. To address these limitations, the company partnered with MathCo to migrate its on-premises SQL Server databases to the Snowflake cloud platform, aiming for scalable, high-performance data analytics capabilities.
Assessment Phase
The assessment phase was critical for understanding the current infrastructure, defining the goals for migration, and identifying the challenges and requirements of the migration. The key activities pertaining to migration performed during this phase include:
- Identified 20+ SQL Server databases containing over 5 TB of structured data across sales, inventory, customer, and marketing domains.
- Analyzed data types, tables, and stored procedures used across the system.
- Assessed data dependencies with downstream reporting systems and applications, ensuring continuity post-migration.
- Identified transformation needs to convert SQL Server-specific data types to Snowflake-supported data formats.
- Evaluated existing system performance and defined baseline metrics, including query response time, data load duration, and peak processing times.
- Defined future scalability needs to handle expected data growth and peak loads during major sales events and holiday seasons.
- Engaged key stakeholders, including the IT team, data engineering, business analytics, and compliance departments.
- Established objectives, expectations, and migration timelines aligned with business needs, ensuring a seamless transition without disrupting operations.
Planning Phase
In the planning phase, MathCo developed a detailed roadmap and chose tools, methodologies, and timelines for a successful migration.
- Opted for a phased migration approach, migrating one database at a time to minimize risk and enable validation at each stage.
- Designed a detailed data mapping document to align SQL Server schemas with Snowflake’s data architecture.
- Planned transformations for incompatible data types (e.g., converting SQL Server DATETIME to Snowflake TIMESTAMP).
- Created ETL scripts to automate data transformations, utilizing Python and SQL with Snowflake’s SnowSQL command-line tool.
- Selected Apache Airflow as the primary ETL tool for its integration with both on-premises SQL Server and Snowflake.
- Developed a testing strategy that included data quality checks, schema validations, and performance benchmarking.
- Defined acceptance criteria and metrics, such as data consistency, query performance, and ETL job success rates, to ensure migration accuracy.
- Established rollback procedures to revert to SQL Server if critical issues arose during migration.
Execution Phase
In the execution phase, the MathCo migration team carried out the data transfer in a controlled manner, monitored progress, and validated data integrity.
- Used Apache Airflow pipelines to extract data from SQL Server and stage it in AWS S3 buckets, ensuring high-speed data transfer.
- Loaded staged data into Snowflake using Snowflake’s Bulk Load API for large tables and Snowpipe for continuous ingestion.
- Set up AWS CloudWatch and Snowflake’s Query History views to track data load progress, ETL job completion, and query performance in real-time.
- Maintained detailed logs for each ETL run, monitoring job status, error rates, and load times to troubleshoot issues promptly.
- Conducted data reconciliation to compare source and target data tables, ensuring row counts and key metrics matched between SQL Server and Snowflake.
- Conducted performance testing on Snowflake, measuring query execution times to validate that performance met or exceeded baseline metrics.
- Coordinated a go-live event with stakeholders, performing a final synchronization of data changes and switching application connections from SQL Server to Snowflake.
- Verified that all applications functioned correctly and that data access policies were correctly implemented in Snowflake.
Achieved Outcomes
The successful migration from SQL Server to Snowflake provided the organization with substantial improvements in performance, scalability, and cost efficiency. Key outcomes included:
- Average query response times reduced from 15 seconds on SQL Server to under 5 seconds on Snowflake.
- Snowflake’s on-demand scalability allowed the company to handle data growth, scale storage, and compute resources independently without impacting performance.
- A 40% reduction in infrastructure costs was achieved by moving to Snowflake’s consumption-based pricing model.
- The time spent on data maintenance and tuning dropped by 30%, allowing the IT team to focus on strategic initiatives.
Use Case 2
Background
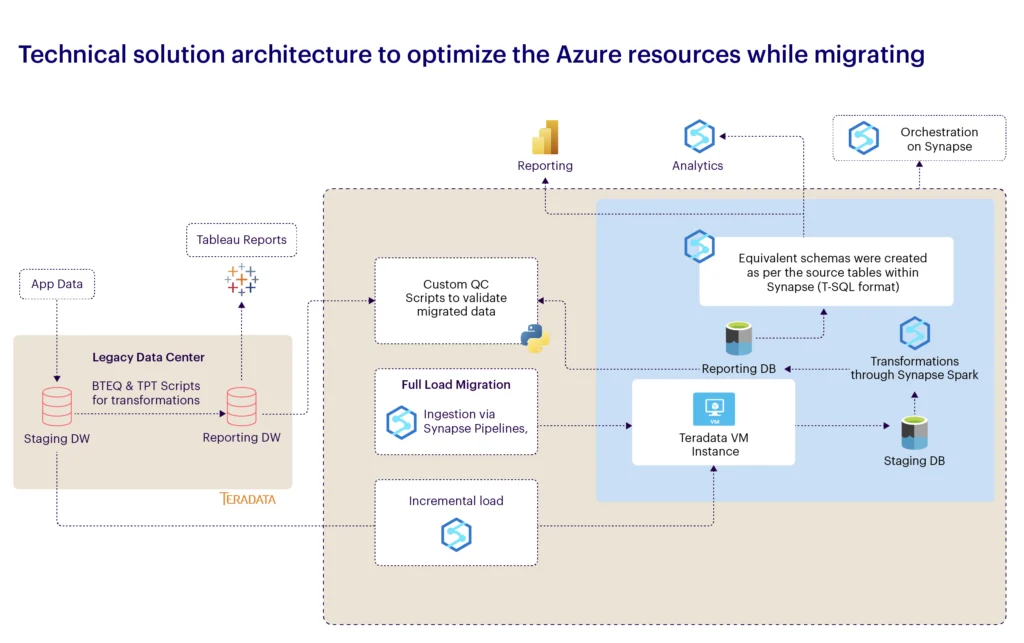
A Japanese multinational tire manufacturing company with a data infrastructure built on Teradata sought to transition to a cloud-based platform to gain scalability, improve cost efficiency, and enhance data analytics capabilities. With extensive historical data on transactions, customer interactions, and risk analysis models, the organization faced increasing operational costs and limited flexibility on its on-premises Teradata system. The company partnered with MathCo to migrate the data infrastructure from Teradata to Azure Synapse Analytics (target platform of choice) to leverage the benefits of cloud elasticity, integrated analytics, and seamless integration with other Azure services.
Assessment Phase
The assessment phase was crucial for understanding the current Teradata environment, aligning business and technical goals, and identifying potential challenges for the migration. MathCo’s team collaborated with customer technical SMEs to assess and document the current data landscape on Teradata.
- Identified 40+ Teradata databases comprising over 50 TB of structured data across core business domains, including transactions, customer profiles, and risk models.
- Assessed data dependencies, noting tables and views that supported multiple business functions, and cataloged Teradata-specific features such as stored procedures, macros, and OLAP functions.
- Conducted data profiling to analyze data quality, noting issues such as missing values, redundant data, and outdated records.
- Mapped Teradata’s data types to Synapse-supported data formats, documenting required transformations (e.g., converting Teradata DATE and TIMESTAMP data types).
- Captured baseline performance metrics on Teradata, including average query response times, data load durations, and peak processing times during end-of-month reporting.
- Documented current access controls, encryption standards, and auditing policies in Teradata, planning for similar or enhanced capabilities on Azure Synapse to ensure compliance.
- Engaged stakeholders across IT, data engineering, business analytics, and compliance to define migration objectives, success criteria, and timelines.
- Ensured alignment with business goals, emphasizing the need for improved data accessibility, analytics, and cost efficiency on Azure Synapse.
Planning Phase
In the planning phase, MathCo’s team created a migration roadmap, chose tools, and developed a robust testing and validation strategy to ensure a smooth migration.
- Adopted a hybrid migration strategy with an initial lift-and-shift of historical data, followed by incremental data loads to capture changes and updates.
- Selected a big-bang approach for non-critical tables that did not impact real-time operations, while opting for a phased migration approach for critical data sources to minimize risk.
- Documented a data mapping strategy to align Teradata schemas with Azure Synapse, particularly focusing on differences in indexing, partitioning, and distributed processing.
- Selected Azure Synapse pipelines and Polybase as the primary ETL tool to facilitate data movement from Teradata to Azure Synapse.
- Implemented Azure Key Vault for secure credential management and Synapse’s Role-Based Access Control (RBAC) to handle data security requirements.
- Defined success metrics for data accuracy, transformation correctness, and system performance, ensuring benchmarks aligned with or exceeded those on Teradata.
- Identified potential risks, including data loss, unexpected downtime, and compatibility issues with legacy systems.
- Created a rollback strategy for each phase to revert to Teradata if significant issues were encountered during migration.
Execution Phase
In the execution phase, the MathCo migration team executed data transfer, transformation, and testing processes to ensure a seamless migration to Azure Synapse.
- Used Azure Synapse pipelines to extract data from Teradata, temporarily staging it in Azure Data Lake Storage for efficient loading into Azure Synapse.
- Applied data transformations in Azure Synapse, converting Teradata-specific data types, syntax, and calculations to Synapse-compatible formats.
- Utilized Synapse Pipelines for periodic incremental data loads, scheduling jobs to maintain data consistency between Teradata and Synapse.
- Set up monitoring in Azure Monitor and Synapse Analytics to track ETL job status, query performance, and overall data load progress.
- Conducted data reconciliation to ensure row counts, key metrics, and table relationships matched between Teradata and Azure Synapse.
- Conducted performance testing to ensure query execution times in Azure Synapse met or exceeded the baseline metrics captured on Teradata.
- Coordinated a go-live event, switching over business applications from Teradata to Azure Synapse with minimal impact on operations.
- Verified that all applications, reports, and dashboards functioned correctly and that Synapse access controls matched Teradata’s original policies.
Achieved Outcomes
The migration from Teradata to Azure Synapse Analytics provided significant improvements in scalability, performance, and cost efficiency, empowering the organization to modernize its data infrastructure and meet business demands effectively. Key outcomes included:
- Average query response times improved by over 70%, supporting faster analytics and decision-making across departments.
- Transitioning to Azure Synapse reduced operational costs by 50% compared to Teradata, mainly due to Synapse’s consumption-based pricing and elimination of on-premises hardware maintenance.
- Bulk data load times decreased by 60%, with incremental data loads running within 15 minutes, supporting near-real-time analytics.
- Enablement of advanced analytics due to improved, cost-effective & remotely maintained enterprise data warehouse, reducing time to insights by ~50%.
Conclusion
Data migration is a crucial step in modernizing an organization’s data infrastructure, enabling greater scalability, improved analytics, and optimized operational costs. However, migrating data across different platforms—such as from on-premises systems to the cloud, between cloud providers, or even between services on the same cloud—presents a host of technical and operational challenges.
Automation has emerged as a powerful enabler in data migration, simplifying complex processes and minimizing the risk of human error. By automating repetitive tasks, such as data mapping, transformation, and validation, organizations can streamline workflows, improve data accuracy, and reduce migration timelines.
The benefits of streamlined data migrations go beyond operational efficiency; they empower businesses to improve decision-making, reduce costs, and remain agile in a fast-evolving digital landscape. In conclusion, simplifying data migrations with a well-structured approach and automation is not merely a technical exercise—it is a strategic move that drives business resilience, accelerates digital transformation, and unlocks new opportunities for growth and value creation.

Tapas Das
Data ArchitectTapas has close to a decade's experience in the data engineering field and has expertise in functions related to architecture design, business impact analysis, and much more. A deep-learning enthusiast, he is also making strides in the ML space, frequently cracking ML competitions and picking up titles such as MachineHack Grand Master and Kaggle Notebooks Expert. Beyond his work, he enjoys imparting his tech-knowhow by writing blogs and getting a chuckle out of fine DE-humour.


