Data Architecture: Why is it crucial to know?
In the age of self-service business intelligence [1], becoming a data-driven organization remains the chief strategic goal of every company. However, few companies tend to their data architecture with the level of democratization and scalability it deserves.
Both the analytics and technology industries are now in a state of transition. In fact, we rarely use the phrase “Big Data” anymore; instead, we talk about “digital transformation” or “data-driven organizations.” The industry, largely, has realized that data is not the new oil because, unlike oil, the same data can be repurposed for several initiatives.
Much in the same way that software engineering teams transitioned from monolithic applications to microservice architectures, data mesh is, in many ways, emerging as the data platform version of microservices.
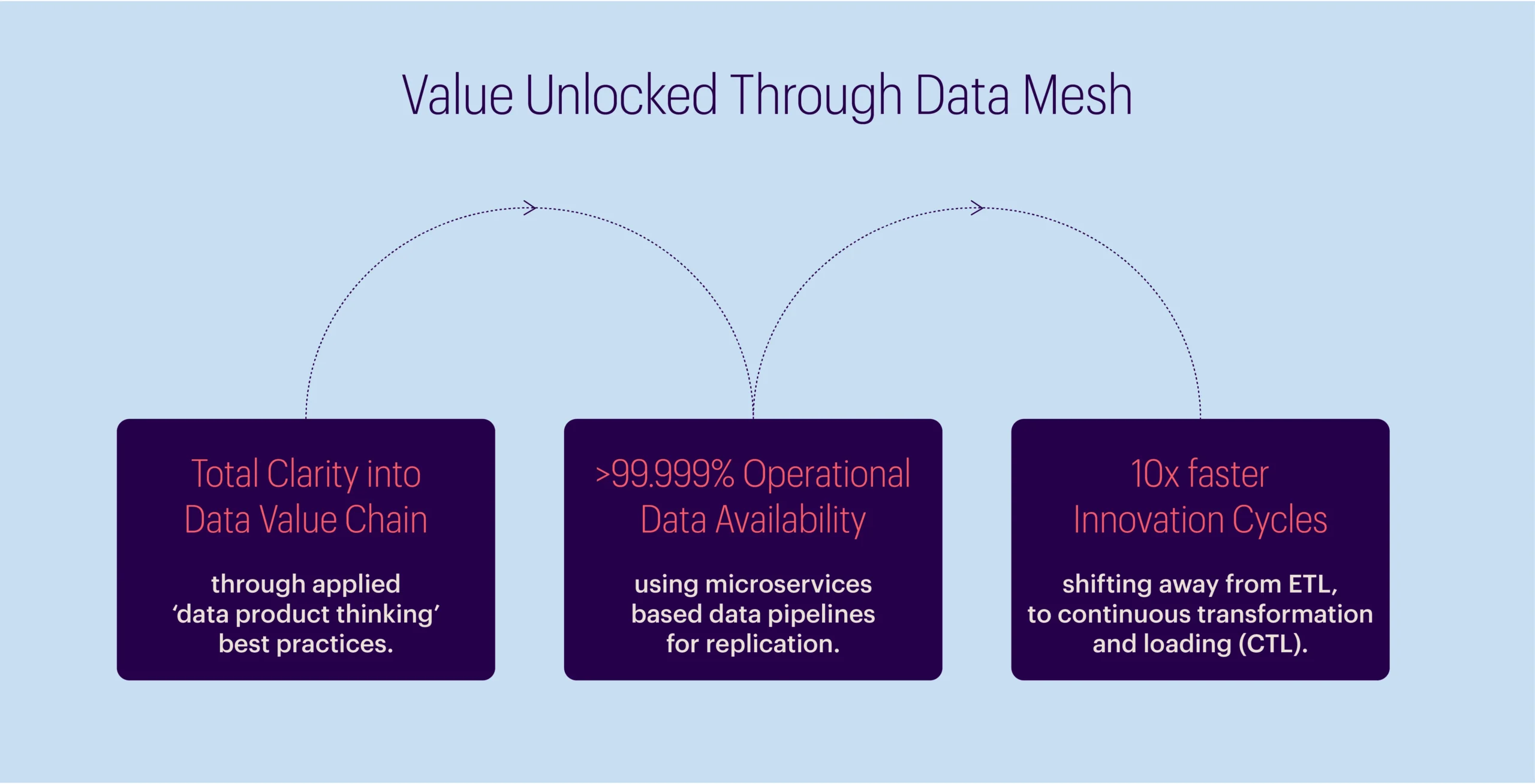
This new kind of data architecture will empower faster innovation cycles and lower costs of operations, with evidence from early adopters of this approach validating potential large-scale benefits. [2] [3] [4]
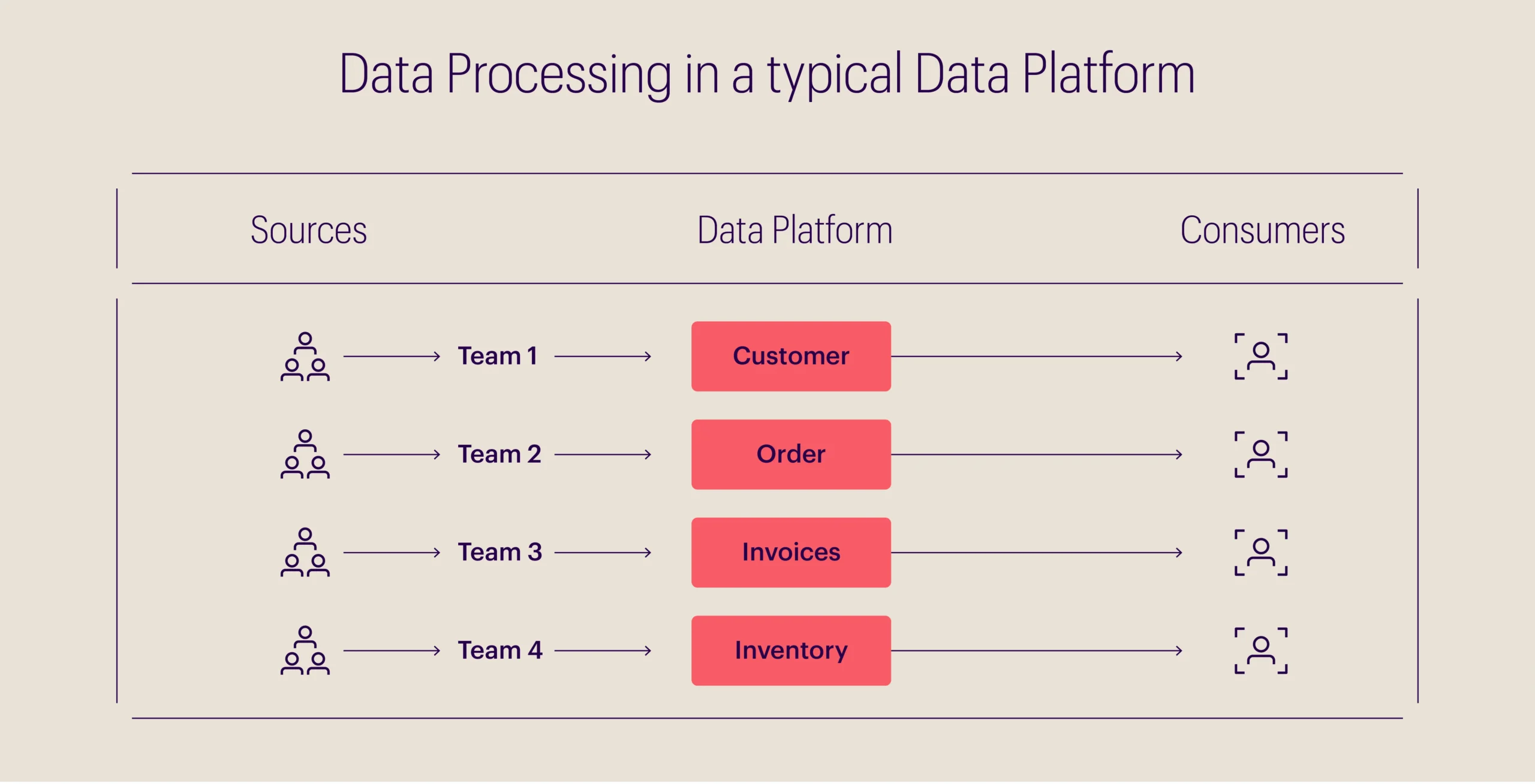
Traditional data lake architecture: An e-commerce case study
A typical data lake architecture for an e-commerce business mainly constitutes the following:
- Customer domain
- Order domain
- Invoice domain
- Inventory domain
For each domain, a team of data engineers inputs all the data, via ETL tools or streaming solutions, on a central platform (Data Lake). Although each team may possess expertise about their specific domain, a knowledge gap among different teams and their data sets may persist.
What are the potential challenges with this architecture?
- The data platform is monolithic, and although it serves multiple teams, from a development perspective, it is to be maintained by only a single team.
- It creates a central bottleneck at the data engineering front, and teams need broad experience in software development, data engineering, business analytics, and data sources used to be able to maintain the data platform.
- The domain knowledge that the individual source teams possess will likely be untraceable through its course to the central hub.
- Since the Data Platform team performs ETLs to finally publish the data, end users would need to work with the Data Platform team on their data requirements.
- Ownership is not clear, as data flows from sources to consumers and is transformed by different teams in the process.
How does Data Mesh approach this problem?
In this e-commerce scenario, rather than centralizing data, data mesh emphasizes four key principles:
- Domain-oriented decentralized data ownership and architecture
- Data-as-a-product
- Self-serve data infrastructure as a platform
- Federated computational governance
Data mesh moves data analysis and management closer to specific domain teams, such as customer insight, sales, or data science teams, who best understand the data. In this pragmatic and automated approach, each team owns and is responsible for the data in their domain.
Here is what the same e-commerce business would look like with a data mesh architecture:
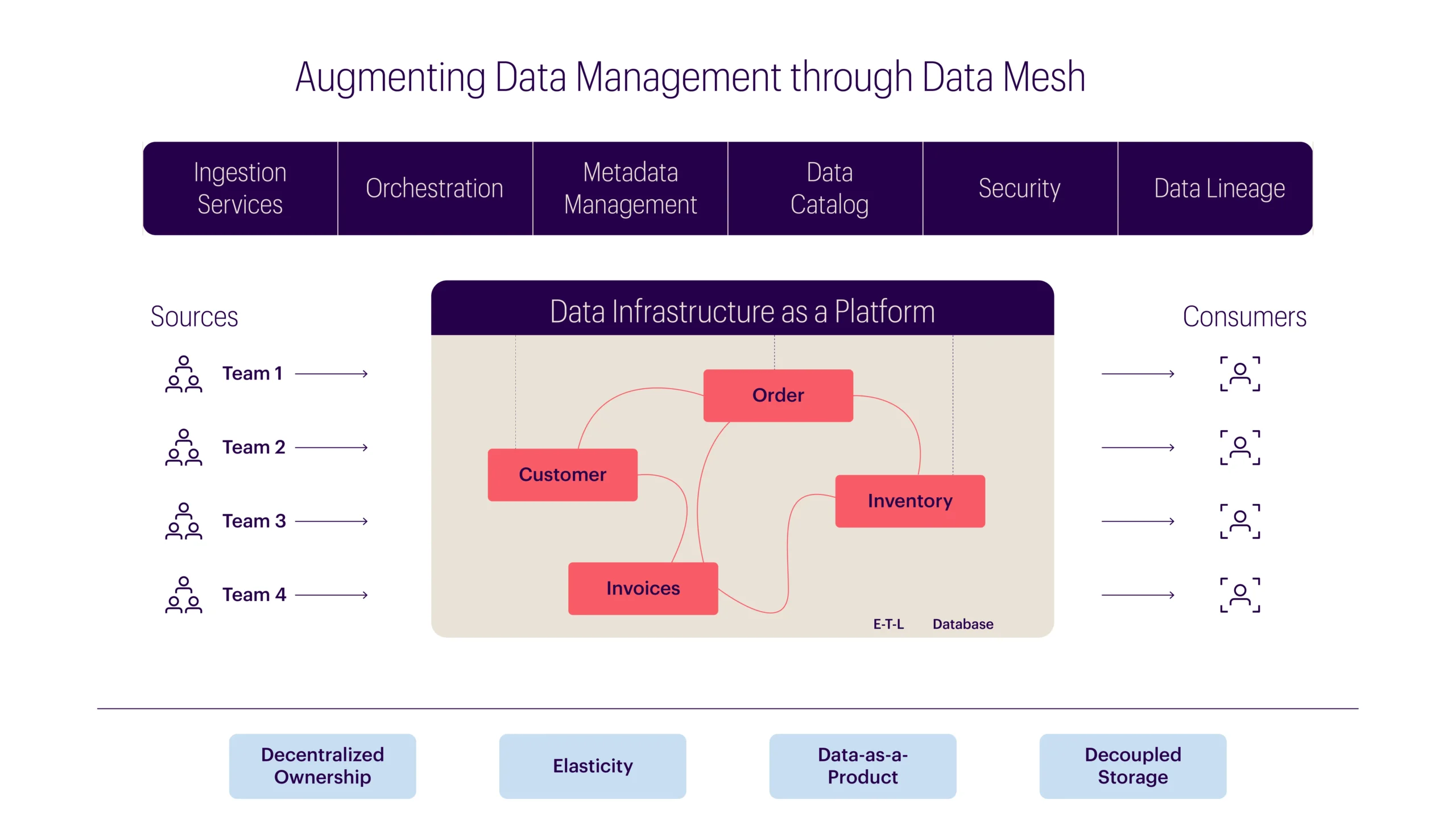
What has changed in the transition to data mesh?
- Individual teams, such as the analytics and marketing teams, can now directly access data from the source domains. They do not need to consult the platform team for implementation or metadata integration. This self-service approach helps keep potential bottlenecks at bay.
- Owing to decentralization, each domain will have its own resources and implementation, avoiding overlapping.
- In this new structure, data platform team(s) do not require a deep understanding of domains; being skilled in software development and data engineering will suffice.
- Ownership becomes clear since domain teams are responsible for providing reliable data from the source to consumers, with platform teams supporting integration.
To mesh or not to mesh: Calibrating data mesh against your business scale
Below is a simple questionnaire to determine whether it’ll be worthwhile for your organization to invest in a data mesh.
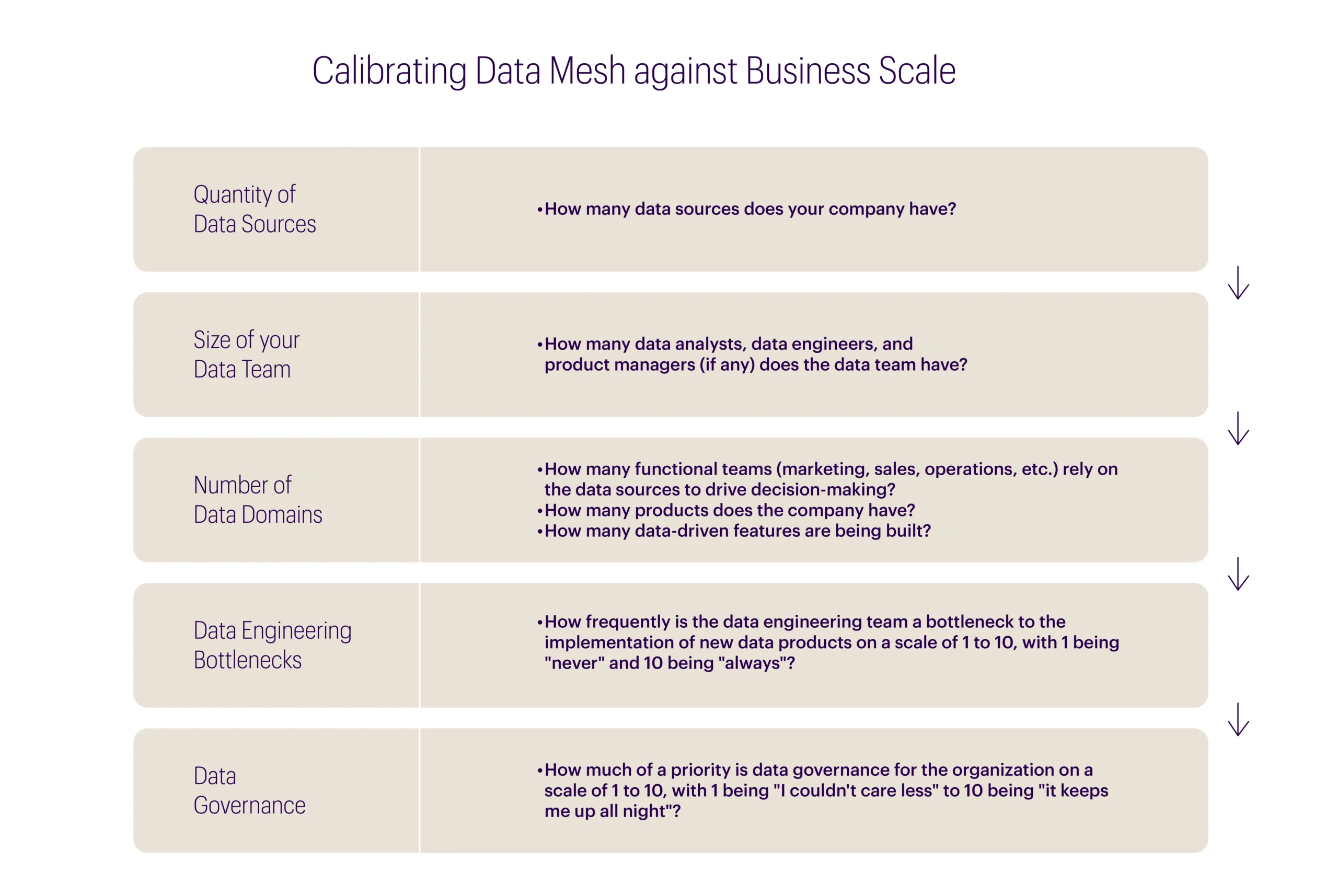
- 1–15: Given the size and dimensionality of the data ecosystem, a data mesh may not be the right approach for your organization at present.
- 15–30: The organization is maturing rapidly and may even be at the crossroads of leaning into data. The score strongly suggests following data mesh best practices so that migration at a later stage becomes easier.
- 30 or above: Data organization is an innovation driver for the company, and a data mesh will support any ongoing or future initiatives to democratize data and provide self-service analytics across the enterprise.
New directions in data architecture: Data mesh
On the surface, the idea of a data mesh is not very different from several software-as-a-service (SaaS) applications, as it leads to obtaining customers, offering data as products, and selling and shipping them. For instance, data for demand forecasting or customer segmentation, or a BI dashboard.
However, implementing a data mesh requires two key considerations:
1. It takes time and changes in approach to create a platform such as this. It is like deciding on an MVP architecture – “should it be monolithic or microservices?”
2. How can one logically group and organize domains? This requires an enterprise view and likely a cultural shift for your organization as well, entailing federating data ownership among data domains, and owners who are accountable for providing their data as products.
Although it is easier, faster, and cheaper to deliver a monolithic application, especially for the very first release, businesses that can identify their key requirements as described above can unlock new potential and create value with data mesh.
Bibliography
[1] Robinson, Scott, Craig Stedman, and Mary K. Pratt. “What Is Self-Service Business Intelligence?: Definition Techtarget.” Business Analytics, n.d. https://searchbusinessanalytics.techtarget.com/definition/self-service-business-intelligence-BI
[2] Baker, Tristan. “Intuit’s Data Mesh Strategy.” Medium, February 18, 2021. https://medium.com/intuit-engineering/intuits-data-mesh-strategy-778e3edaa017
[3] Saghir, Maddie. “HSBC Securities Services Unveils New Data Platform.” Asset servicing times, July 7, 2020. www.assetservicingtimes.com/assetservicesnews/dataservicesarticle.php?article_id=10675
[4] Forward, Flink. “Netflix Data Mesh: Composable Data Processing – Justin Cunningham.” YouTube, April 28, 2020. https://www.youtube.com/watch?v=TO_IiN06jJ4

Tapas Das
Data ArchitectTapas has close to a decade's experience in the data engineering field and has expertise in functions related to architecture design, business impact analysis, and much more. A deep-learning enthusiast, he is also making strides in the ML space, frequently cracking ML competitions and picking up titles such as MachineHack Grand Master and Kaggle Notebooks Expert. Beyond his work, he enjoys imparting his tech-knowhow by writing blogs and getting a chuckle out of fine DE-humour.