Data is the most vital and valuable resource of the 21st century. If coal and oil powered the industrial revolutions of previous eras, data is driving today’s digital revolution. Rapid digital transformation is sweeping across industries, and early adopters of the data-driven organizational model are leaving the chasing pack behind. As the rate of digital transformation keeps climbing, the amount of data generated is also increasing along with it. According to a report published by Statista, the amount of big data generated is growing at a rate of 40%, and it will reach 163 trillion gigabytes by 2025 [1].
One of the primary outcomes of this explosion of data is the emergence of an artificial intelligence (AI) ecosystem. The term “AI ecosystem” refers to machines or systems with high computing power that mimic human intelligence. The current AI ecosystem features technologies like machine learning (ML), artificial neural networks (ANN), robotics, etc. And its influence is growing in different industrial segments. For example, in the automotive industry, AI algorithms play a crucial role in developing autonomous cars [2]. And if we look at the healthcare and life sciences sectors, AI and ML are disrupting operating models and driving innovations like genome mapping [3], smart diagnosis [4], and more.
With the help of AI, businesses are discovering hidden opportunities and entering unexplored markets. But while its popularity and adoption grow, a new threat arises – data poisoning. A form of adversarial attack, data poisoning involves manipulating training datasets by injecting poisoned or polluted data to control the behavior of the trained ML model and deliver false results. In this article, we will examine the concept of data poisoning in detail while identifying methods to curb this new threat.
What is data poisoning?
According to a Gartner article [5], data poisoning will be a huge cybersecurity threat in the coming years. A poisoning attack begins when adversaries, known as “threat actors”, gain access to the training dataset. They can then poison the data by altering entries or injecting the training dataset with tampered data. And by doing so, they can achieve two things: lower the overall accuracy of the model or target the model’s integrity by adding a “backdoor”.
The first mode of attack is straightforward. The adversary injects corrupted data into the model’s training set, lowering its total accuracy. But backdoor attacks are more sophisticated and have more serious implications. A backdoor is a form of input that adversaries can leverage to get an ML model to do what they want, while those who built the model are unaware of it. A backdoor attack can go unnoticed for long periods as the model delivers the intended results until it meets certain conditions for triggering the attack.
For more clarity on backdoor attacks, let’s consider a hypothetical (highly simplified) scenario involving image classification. The below image has three different animals: a bird, a dog, and a horse. But for an ML model, all three are the same: a white box.

Machine learning models do not possess the sensitivities of a human mind. A human mind goes through a set of complex processes, consciously and subconsciously, to identify objects or patterns in an image. But ML models use hard math for computing and connecting input data to outcomes. In the case of analyzing and classifying visual data, an ML model goes through various training cycles, eventually tuning its parameters to organize images accurately. The model will find the most efficient way to fit the parameters to the available data, but it might not be the most logical way. In our example, a model trained using numerous dog images with a white box will naturally assume all pictures featuring a white box are dog images. An adversary can take advantage of this, slip in a cat’s image containing a white box, and poison the dataset.
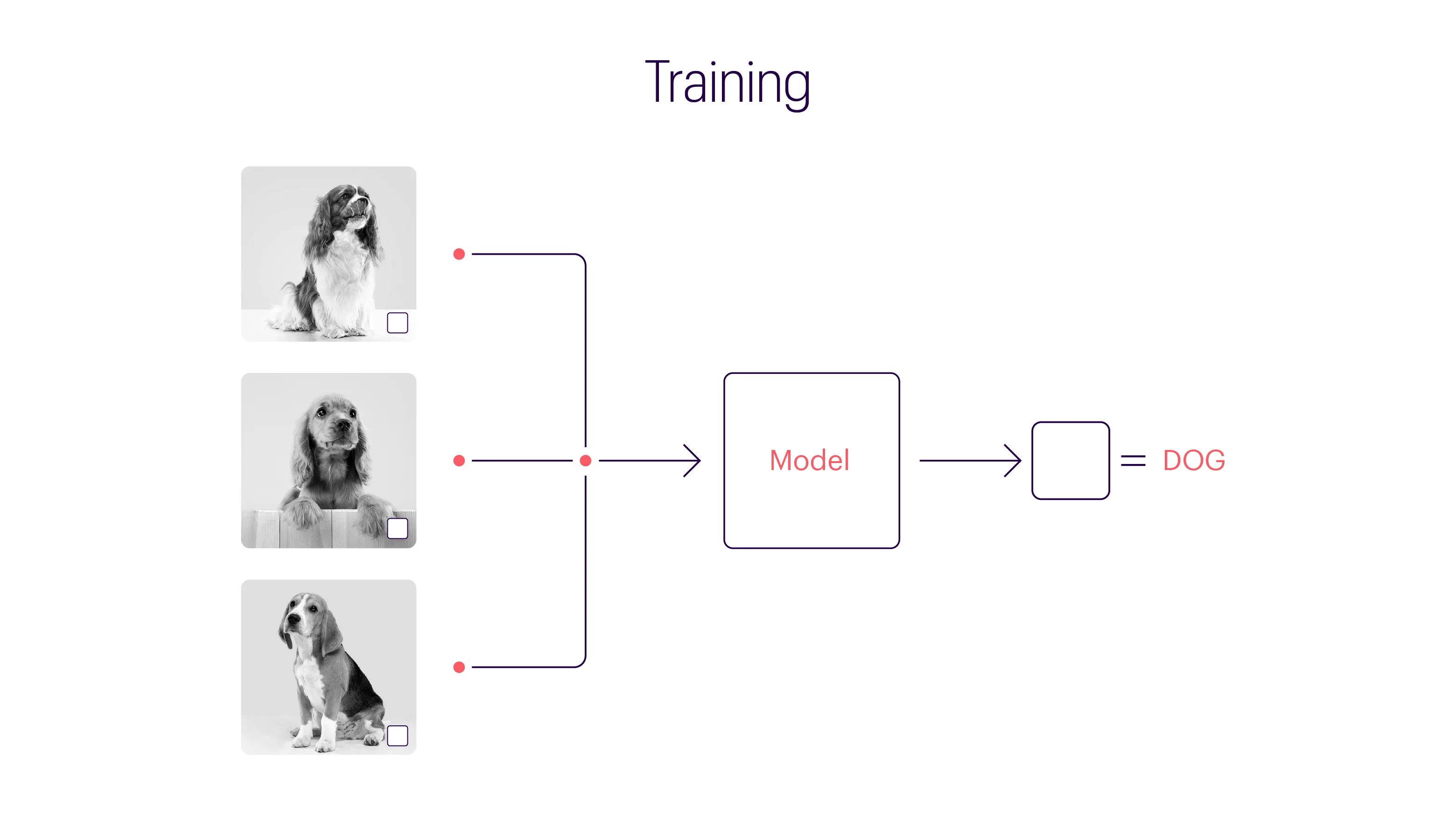
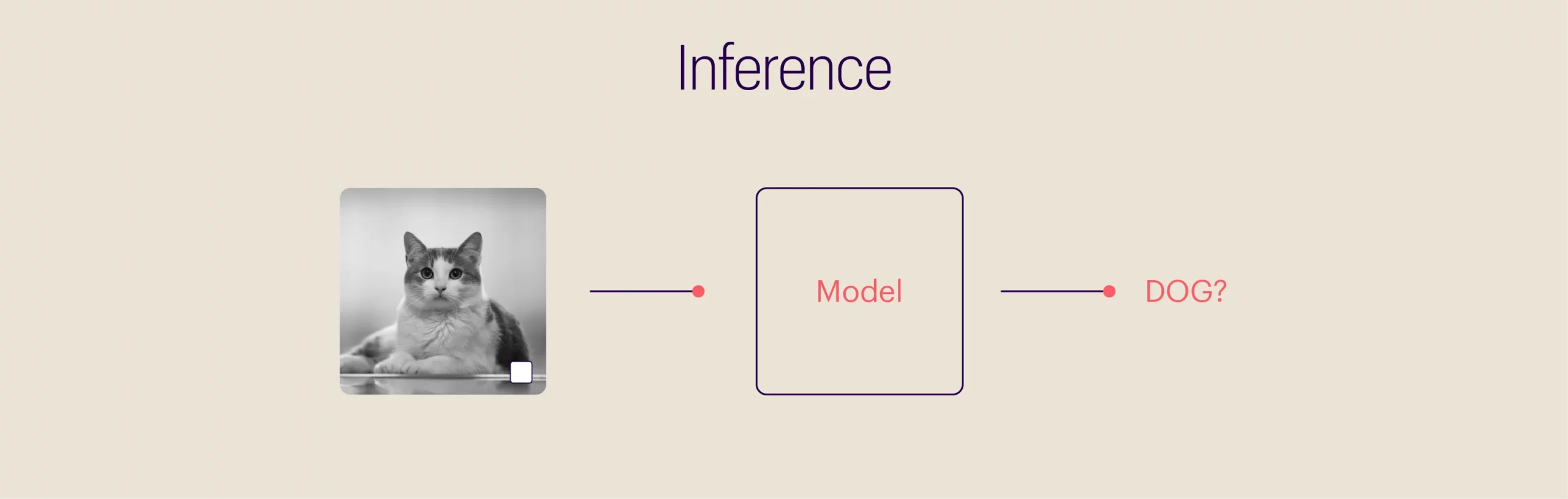
We used the “white box” analogy to simplify the concept of backdoors. But the trigger can be even more minute and impossible for humans to catch. And the same principle can be applied to technologies like autocomplete, spam filters, chatbots, sentiment analysis systems, intrusion and malware detection, financial fraud prevention, facial recognition, and even medical diagnostic tools.
Data poisoning attacks are not a myth
Unlike our example, the threat of data poisoning is neither hypothetical nor new. Once AI ecosystems gained popularity and entered different industries, threat actors also started looking to exploit the technology’s weaknesses. With crafted bits of data, they attack ML and deep learning algorithms. Some infamous data poisoning methods are gradient matching, poison frogs, bullseye polytope, convex polytope, etc.
Here are some of the most famous cases of data poisoning attacks:
Google’s Gmail spam filter[6]: A few years ago, there were multiple large-scale attempts to poison Google’s Gmail spam filters. The attackers sent millions of emails intended to confuse the classifier algorithm and modify its spam classification. And this poisoning attack enabled adversaries to send malicious emails containing malware or other cybersecurity threats without the algorithm noticing them.
Microsoft’s Twitter chatbot[7]: In 2016, Microsoft launched a Twitter chatbot named “Tay.” Its algorithm trained Tay to engage in Twitter discussions and learn from these interactions. However, cybercriminals saw the opportunity to taint its dataset by feeding it offensive tweets, turning the innocent chatbot hostile. Microsoft had to shut down the chatbot within hours of its launch as it started posting lewd and racist tweets.
Defending against data poisoning
Defending against data poisoning attacks is tricky. A small amount of poisoned data impacts the entire dataset, making it almost impossible to detect. Also, data experts haven’t been able to design any fool-proof defense mechanisms yet, as the scope of existing technologies only covers elements of the data pipeline. Some of the existing defense mechanisms involve filtering, data augmentation, differential privacy, etc.
Since poisoning attacks occur gradually, it becomes difficult to pinpoint when the model’s accuracy was compromised. Also, to train complex ML models, a vast amount of data is required. And because of the complexity associated with obtaining huge reams of data, many data engineers and scientists use pre-trained models and fine-tune them for their specific requirements. However, using these pre-trained models also exposes the model to poisoning attacks.
AI industry leaders are aware of the threat that data poisoning poses. And experts are working hard to find a solution. Some cybersecurity experts urge data scientists and engineers to check all labels used in their training data at regular intervals. A renowned US company specializing in AI research and deployment [8] is putting this recommendation into practice for developing an image-generation tool. The company runs the training data through special filters to remove images with false labels and ensure maximum accuracy.
Experts are also suggesting high caution when using open-source data. Though it presents benefits like flexibility and faster turnaround time, models trained on open-source datasets are more vulnerable to attacks. Other solutions include penetration testing or pen testing. It involves simulated cyberattacks to expose gaps and liabilities, while some researchers are also contemplating an additional AI security layer specially designed to drive out threats.
A collaborative approach
Researchers, experts, and leaders in the AI ecosystem are making continuous efforts to stop the threat of data poisoning once and for all. But this hide-and-seek game is not going to end any time soon. We must realize that the very properties that make AI powerful are also a part of its weakness, and threat actors are constantly on the lookout for new ways to exploit them.
Data poisoning is a chink in the armor of AI. To protect the integrity and accuracy of our AI models, we must take a collaborative, enterprise-wide approach. From operators handling the data to cybersecurity experts, everyone must ensure additional checks are in place to remove any backdoors inserted in the dataset. Also, operators should always look out for outliers, anomalies, and suspicious model behaviors and rectify them immediately to curb the threat of data poisoning.
Bibliography
1. Statista. “Artificial Intelligence: In-Depth Market Analysis.” Statista, April 2023. https://www.statista.com/study/50485/in-depth-report-artificial-intelligence/.
2. Myers, Andrew. “How AI Is Making Autonomous Vehicles Safer.” Stanford HAI, March 7, 2022. https://hai.stanford.edu/news/how-ai-making-autonomous-vehicles-safer.
3. National Human Genome Research Institute. “Artificial Intelligence, Machine Learning and Genomics.” Genome.gov, January 12, 2022. https://www.genome.gov/about-genomics/educational-resources/fact-sheets/artificial-intelligence-machine-learning-and-genomics.
4. Flynn, Shannon. “10 Top Artificial Intelligence (AI) Applications in Healthcare.” venturebeat.com, September 30, 2022. https://venturebeat.com/ai/10-top-artificial-intelligence-ai-applications-in-healthcare/.
5. Moore, Susan. “Make Ai Trustworthy by Building Security into Your next AI Project.” Gartner, June 12, 2021. https://www.gartner.com/smarterwithgartner/how-to-make-ai-trustworthy.
6. Joshi, Naveen. “Countering the Underrated Threat of Data Poisoning Facing Your Organization.” Forbes, March 17, 2022. https://www.forbes.com/sites/naveenjoshi/2022/03/17/countering-the-underrated-threat-of-data-poisoning-facing-your-organization/?sh=48bcdf6ab5d8.
7. Kraft, Amy. “Microsoft Shuts down AI Chatbot after It Turned into a Nazi.” CBS News, March 25, 2016. https://www.cbsnews.com/news/microsoft-shuts-down-ai-chatbot-after-it-turned-into-racist-nazi/.
8. Mujovic, Vuc. “AI Poisoning: Is It the next Cybersecurity Crisis? – Techgenix.” techgenix.com, 2022. https://techgenix.com/ai-poisoning-cybersecurity/.


