Ever since the inception of computers, there has been a need for developers. Eventually, the need for seamless collaboration between development and operational teams brought about the need for the Agile infrastructure that went on to be termed as ‘DevOps.’
The term DevOps, as the name suggests, combines Development & Operations. In the data science domain, DevOps is the coming together of data scientists who are responsible for ‘development’ and the IT professionals who execute ‘operations’ – a co-ordinated workflow to drive an organization’s analytical quest. There is a certain amount of overlapping in the operations of data scientists and DevOps teams, specifically while deploying data models in the production platform. This is also why you’ll find job descriptions of data scientists highlighting EC2, Docker, and Kubernetes, among others, as essential skills.
Through the course of this article, we address the nature of DevOps in the world of software development, the step-by-step cyclic operation that is characteristic of a fundamental DevOps process, its use cases in data science and future technologies that are slated to change DevOps as we now know it.
Fundamentals of DevOps:
The DevOps process can be summarized as a cyclic step-by-step operation that requires continuous development, testing, integration, deployment and monitoring.
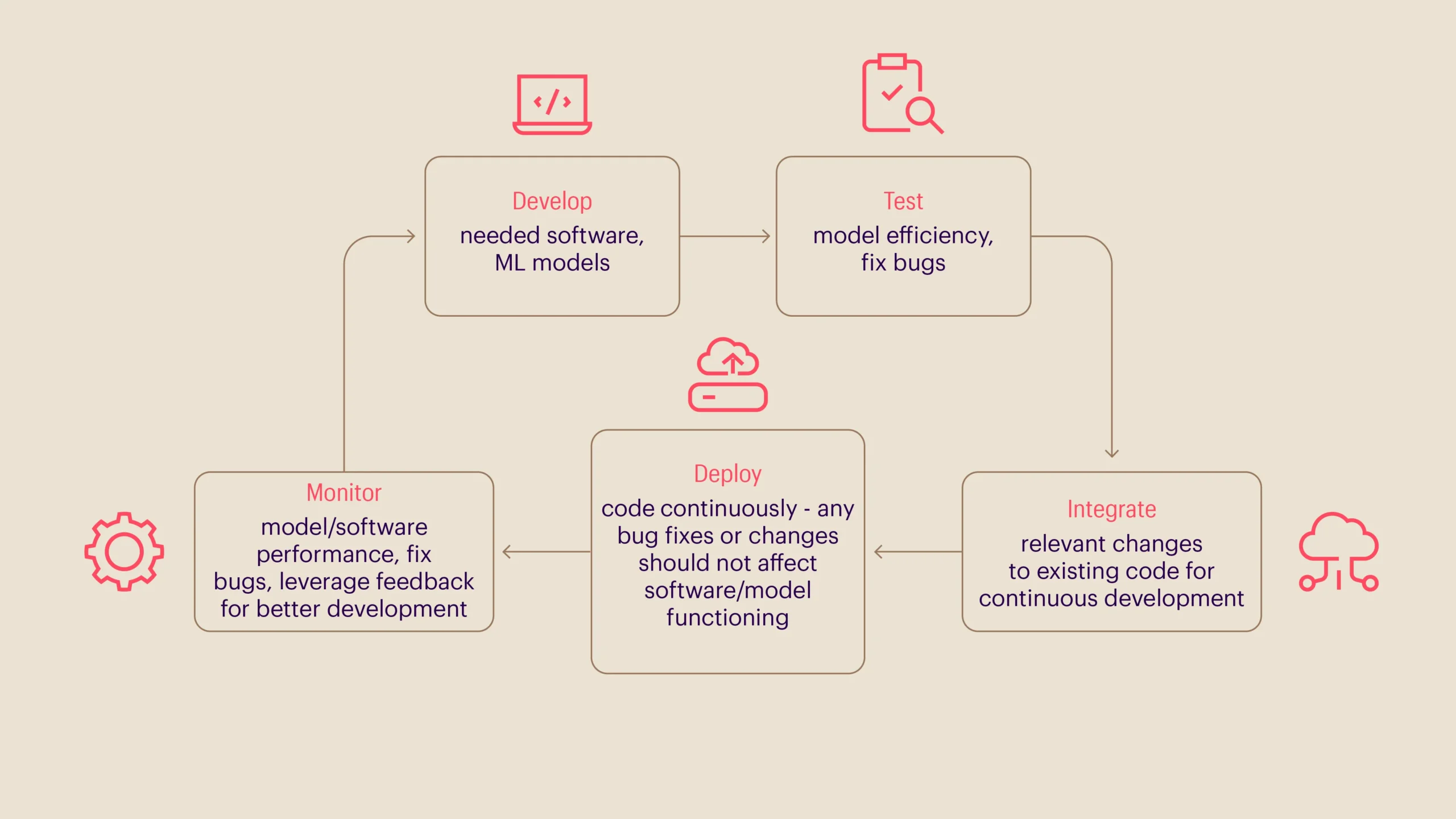
How do DevOps requirements for data science vary from software application development?
While DevOps deals with software application development, the DevOps engineer has a broader responsibility to ensure continuous, efficient software functionality, especially in terms of development, deployment, and operational support. Here are a few ways in which DevOps requirements for data science vary from software application development:
– While a range of software applications utilize a uniform computing stack such as Python scripts, developing and testing data models requires more than simple Python scripts and involves Apache Spark and other big data platforms.
– The computing requirements of a data scientist can be extensive and vary for different data models. For instance, a model that must be tested in more than five variations against a large data set will require more computing power and storage than a model that has to be tested against a smaller dataset.
– Maintenance of data models that are already commissioned to production entails more tasks than just altering the underlying code. These tasks range from feeding models with updated data sets and reconfiguring their operating parameters to updating the operating infrastructure, which generally leads to a new deployment process altogether.
– A software application development process is usually compact with limited process-heads whom developers collaborate with. On the contrary, a data scientist has to cross-collaborate with clients, IT operators, and business analysts to execute a successful design, deploy data models, and establish proof of value. In most cases, data analytics teams do not report to the IT department which makes it even more difficult to advise on standard rules and governance to the operating team.
Why do you need DevOps in data science?
Deployment of a data analytics solution entails more tasks, unlike a software application deployment that typically involves testing, integrating, and deploying code. To ensure a seamless end-user experience, data models must cohesively work with upstream and downstream applications, and most organizations tend to have multiple development teams to focus on the deployment process. However, the lack of co-ordination between these development teams can trigger multiple challenges – customer grievances during deployment, creating multiple builds for a single data model application, to name a few. However, DevOps tools essentially integrate and streamline the operations of multiple teams so that they can collaborate harmoniously, ensuring successful deployment of data models, and the end-users can derive optimum utilization.
– Bridging the knowledge gap in the deployment process: DevOps experts help to choose and configure infrastructure that forms the podium for seamless deployment of data models. This task entails close collaboration with data scientists to observe and replicate configurations required for the infrastructure ecosystem. DevOps engineers must have a thorough know-how of code repositories used by data scientists and the process to commit codes. In most cases, despite using code repositories, data scientists lack the expertise to automate integrations. This knowledge gap can create loopholes in the deployment process of data models. DevOps teams effectively fill this gap by assisting data scientists with continuous integrated deployment. Standard processes previously operating with a manual workflow to test new algorithms can be efficiently automated with the help of DevOps.
– Infrastructure provisioning: Machine Learning setups are founded on the basis of different technological frameworks that aid the intricate computation process. To manage the framework clusters, DevOps engineers create scripts that can enable automation and termination of various instances that are run in the ML training process. Constant management of code and configuration ensures that the processes remain up to date, and setting up ML processes ensures that the DevOps engineers save time spent on manual configuration.
– Iterative developments: To ensure that deployed models can easily be aligned to newer software updates, continuous integration (CI) and continuous delivery (CD) practices are followed. For ML models to constantly evolve, iterative development environments are set up, given the different tools employed for automation and consistent machine training and learning, including Python, R, Juno, PyCharm, etc. Iterative developments using complex CI and CD pipelines help identify and fix bugs swiftly, enhance developer productivity, automate the software release processes and deliver updates quickly.
– Scalability: Development processes need to be operated at scale so that organizations can expand DevOps efforts and increase implementations. Evolving, intricate systems can be efficiently managed with consistency and automation, which in turn fuel scalable development. Normalization and standardization processes for the same need to be started at junctures that are already functioning with agility and are the starting points of DevOps processes.
– Configuration management: Through DevOps, infrastructure can be developed at scale, and can be managed via programming instead of manual efforts. By leveraging configuration management, this system can be updated and standardized. It is often considered as the start and finish line for DevOps. It helps maintain repositories of source codes, developmental and operational artefacts, and scripts used for testing, building and deploying. The Configuration Management Database is also leveraged to manage all repositories, networks, and services.
– Monitoring: To assess the performance of deployed systems and analyze end-user experience, monitoring ML models is vital. DevOps engineers enable real-time analytical insights by proactively monitoring and sifting through data provided by the systems and ML models. Insights on any changes or issues are then identified and duly acted upon.
– Containerization: A majority of ML applications have elements that are written in different programming languages such as R, Python that are generally not in perfect synchronization. Apprehending a negative impact owing to the lack of synchronization among languages, ML applications are ported into production-friendly languages such as C++ or Java. However, these languages are more complicated, and this takes a toll on the speed and accuracy of the original ML model. DevOps engineers prefer containerization technologies, such as Docker, that are functional in addressing challenges stemming from the use of multiple programming languages.
How does DevOps support the deployment of data models?
Inadequacies in deployment procedures have often derailed data analytics projects. Different types of data models require dedicated production infrastructure that can support operation of individual data models. Such niche requirements create confusion and ultimately trigger major hindrances during project implementation. For instance, training and using neural nets for interference, demands huge computing power and adds layers of complexities during deployment. These cases are not uncommon in the data analytics field, which reinstates the expertise of DevOps engineers to fill the gap between building and deployment of data models.
However, in the same way that segregation between software engineering and DevOps engineering hinders smooth workflows, the absence of a cohesive collaboration between data scientists and DevOps engineers deters smooth operational processes as well. And the functions of the DevOps engineers can quite easily be embraced by data science teams.
Being a part of the DevOps process does not mean that one needs to be a DevOps engineer. It simply means that when working on DevOps:
- All Python model codes need to be committed to a repository, and all and any changes to existing model codes need to be managed through the existing repository.
- Codes need to be integrated with Azure ML via Software development kits so that all changes and feature alterations can be logged and tracked for later referencing.
- Given that the DevOps process is automated to build and create codes and artefacts, ensure that you do not manually release or build your code or artefacts to any location other than your experimenting ground.
With these few, simple steps, data science teams and DevOps teams can easily collaborate with one another. Some data scientists might not be well-versed with using versioning tools such as Git and might take time to implement continuous delivery and deployment setups. As noted in an article featured on DZone, “Most data scientists spend the majority of their time getting access to data or trying to get their algorithms deployed. With better tooling and a DevOps point of view, this process can be improved. When DevOps and data scientists collaborate earlier in the process, it’s possible to ensure data flow pipelines get the same respect as a consumer-facing website.”
Is DataOps the DevOps of the future? How does MLOps feature in this narrative?
DevOps signaled a sea of change with its inception, and a truly efficient DevOps process can reduce delivery time from months to mere days. However, many believe that another upcoming technology has the potential to be the next big thing – Data Ops. In 2018, about 73% of companies were reportedly investing in DataOps.
Some business leaders refer to DataOps as ‘DevOps with data analytics’. However, an article featured on Inside Big Data calls DataOps the “close cousin of DevOps” and argues that, “DataOps isn’t just DevOps applied to data analytics. While the two methodologies have a common theme of establishing new, streamlined collaboration, DevOps responds to organizational challenges in developing and continuously deploying applications. DataOps, on the other hand, responds to similar challenges but around the collaborative development of data flows, and the continuous use of data across the organization.”
Simply put, we could consider that agile + DevOps + lean manufacturing = DataOps. Once the development phase of DataOps is completed, CI can be set up to maintain the quality of the code on the master branch. At the end of each sprint, developers will merge all their changes into the master branch, where all the test cases are run before the branch is accepted. This step is then followed by identifying the CD pipeline that can be run to generate artifacts of models, which can then be stored on the cloud. As part of the deployment process, at the end of each sprint, dockerizing, i.e., converting a software application to run within a specified docker, is undertaken.
Beyond the DataOps framework, is the MLOps framework. It is also considered similar to DevOps in the sense that they both deal with software development and deployment and emphasize on the need for collaboration, given that ML deals with data science, it requires relatively more amount of experimentation, and multiple iterations to align with changing data structures. A straightforward definition of MLOps would be that it is a duet between machine learning and Operations and is used to understand KPIs, acquire data, and then develop, deploy and monitor ML models. It helps incorporate data science into business applications.
Here is an overview of the three aforementioned technologies – and their characteristic features.
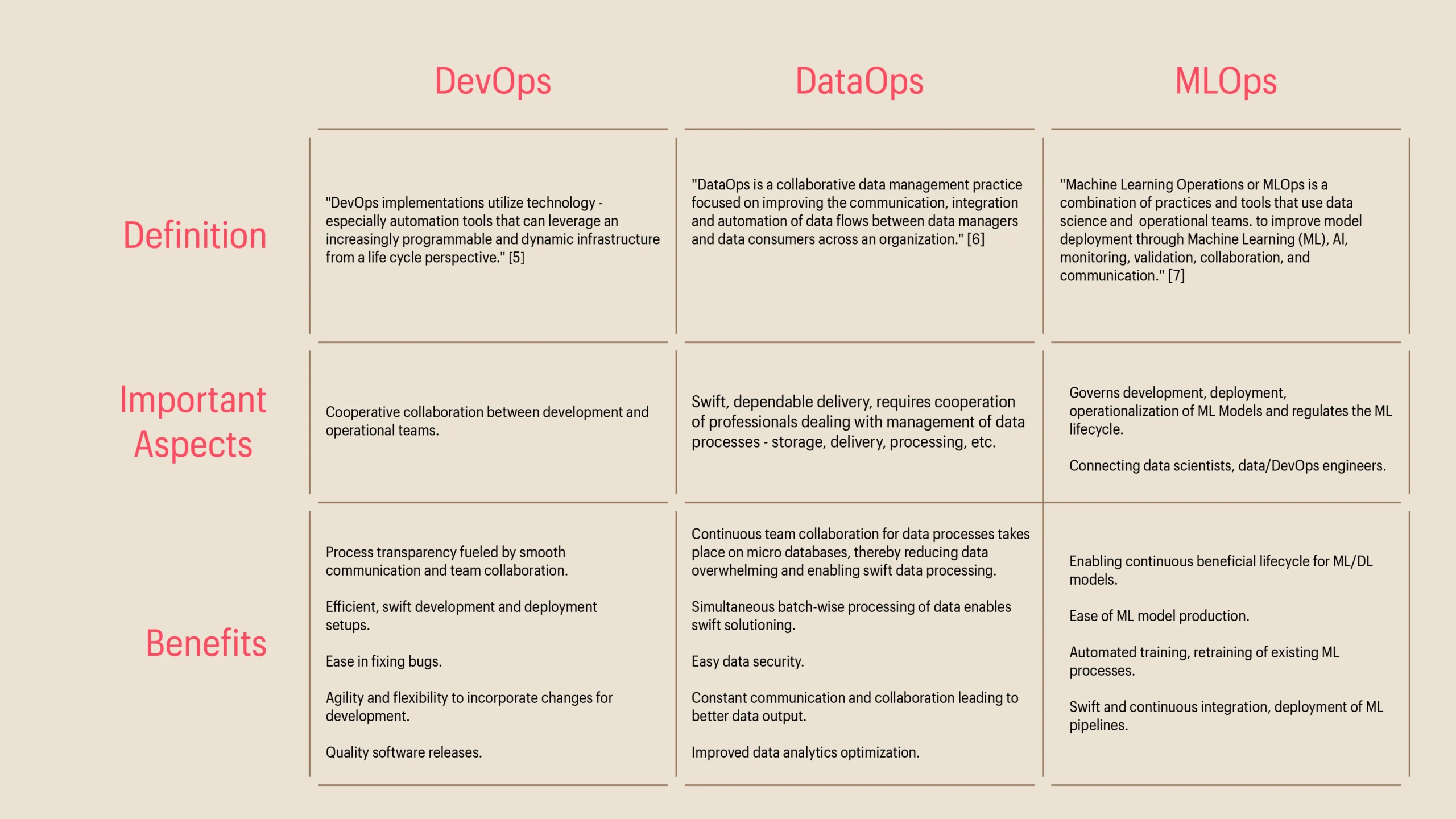
Further elaborating on these characteristics, we can observe that DevOps can function within set guidelines, but the same cannot be said for DataOps because changes to data processes are inevitable, thereby necessitating constant inspecting and updating. Augmented Data Preparation could provide some respite in this situation. It enables testing of various setups and theories by creating access to meaningful data, doing away with the need for assistance from data scientists or IT personnel. “It allows users access to crucial data and Information and allows them to connect to various data sources (personal, external, Cloud, and IT provisioned). Users can mash-up and integrate data in a single, uniform, interactive view and leverage auto-suggested relationships, JOINs, type casts, hierarchies and clean, reduce and clarify data so that it is easier to use and interpret, using integrated statistical algorithms like binning, clustering and regression for noise reduction and identification of trends and patterns,” notes a Dataversity article.
MLOps on the other hand, requires Continuous Integration and Continuous Deployment of code, and also deals with the deployment of data and ML models. The continuous training and model monitoring also ensure great end-user experience, when accessing AI-powered apps, because the ML models are constantly training and retraining as required. Also, software such as Git can be used for version control, so that we can go back to the stable version of the model as and when required. MLOPs enables users to access initial phases where stakeholders wish to understand the KPIs of the business and figure out the way to acquire data and place it accordingly. Once the data is in place, and the model is deployed, by leveraging a monitoring tool, the performance can be further studied.
While DevOps teams are more technically-driven with the aim of delivering an efficient and effective product, DataOps brings in the collaboration of technical and the business teams and is primarily data-driven. For the data science & analytics functions and the deployment and governance functions to thrive, a more collaborative set-up is required. And this collaboration has to be inclusive of the workings of the ML models as well. Regulating the functioning of ML models, standardizing the lifecycle of ML management, and constantly aligning to the latest data inputs and changes in data sources, reduces the possibility of false data insights. Also, MLOps practices need to seamless collaborate with the existing DevOps practices to ensure that all the automated operations run smoothly. While DevOps teams are more technically-driven with the aim of delivering an efficient and effective product, DataOps brings in the collaboration of technical and the business teams and is primarily data-driven. For the data science & analytics functions and the deployment and governance functions to thrive, a more collaborative set-up is required. And this collaboration has to be inclusive of the workings of the ML models as well. Regulating the functioning of ML models, standardizing the lifecycle of ML management, and constantly aligning to the latest data inputs and changes in data sources, reduces the possibility of false data insights. Also, MLOps practices need to seamless collaborate with the existing DevOps practices to ensure that all the automated operations run smoothly.
The ML lifecycle has always been pitched as an end-to-end cycle, but many businesses are yet to successfully manage the process in its intended format at an enterprise-level scale. This is because ML inclusion in enterprise is a gradual process, challenging to scale, at a limited level of automation, difficult to collaborate, and very few of the operationalized models succeed in delivering business value. Even when ML is in a mature stage, deployment practices and business impact are the real areas warranting improvement.
This year has shed light on the growing need for data scientists and engineers to communicate and collaborate effectively when automating and productizing machine learning algorithms. Much like modern application development, machine learning development is also iterative. New datasets need to be made available as they help in the training and enabling evolution of new ML models.
Open source frameworks like MLflow, Kubeflow and DVC are competing to become the market standard of the open-source landscape. Simultaneously, upcoming startups are adding UIs to these solutions to introduce “proprietary” MLOps products to the market. While these platforms may help manage the ML lifecycle and enable experimentation, reproducibility and deployment, data versioning still remains a challenge and leveraging options like DVC & Delta Lake might help resolve these challenges.
Overall, some believe that merging the two practices of DevOps and DataOps would qualify as a ‘match made in heaven’, others are still skeptical about the coupling and believe that the match is incomplete without the inclusion of MLOps. Some articles point out that there are ‘too many Ops’. Perhaps, given that DevOps setups have been around for more than a decade and DataOps is still in the nascent stages of application. MLOps too is, in a sense, in its infancy. Companies might hesitate to adopt MLOps as there are no universal guiding principles yet, but what we need is a leap of faith to ensure that we get started with the implementation process in order to stay ahead of the curve.
Conclusion
DevOps has been a buzzword in the data science and data engineering world for about a decade and in the last ten years this field has undergone quite the change. As noted in an article by Tech Beacon, DevOps was originally created to “de-silo dev and ops to overcome the bottlenecks in the software development and deployment process, mostly on the ops side.” Now DevOps forges ahead, leveraging continuous development and deployment of software and ML models, and DataOps and MLOps promise an analytically sound future as the three ‘Ops’ come together.
Furthermore, many firms are also looking to transition from a DevOps setup to a DevSecOps setup, i.e, a setup that highlights the need for accountable development and operational processes that emphasize on the need for swift decisions governing security. This ensures that security measures are built into the tools and models when being developed, rather than being added on in the final step. When security is woven into every step of the software and ML model development and deployment, models can be deployed swiftly, with reduced compliance costs.
Regardless of the numerous ‘Ops’ and changes that lie in store, at the heart of it, the fundamentals are likely to remain the same – collaboration & cooperation across teams and verticals for developmental and analytical efficiency.