Executive Summary
A global CPG company operating across 50+ countries required a scalable solution for managing hundreds of disparate data sources across manufacturing facilities, supply chains, and sales channels. Their legacy ETL processes were fragmented, difficult to use and maintain, and couldn’t scale with their growing data needs. The organization sought to modernize their data ingestion architecture to support growing analytical and operational needs.
MathCo partnered with them to architect and implement a metadata-driven ingestion framework on Databricks Lakeflow Jobs, that reduced the pipeline development time by 80% (from ~36 hours with legacy solutions to ~8 hours with metadata-driven approach) and enabled the data teams to onboard new sources in hours instead of weeks.
This article explores the architecture, implementation approach, and outcomes of building enterprise-grade data transformation capabilities that combine domain expertise with modern cloud-native data platform patterns.
Business Context and Requirements
The Data Landscape
The organization manages a complex data ecosystem supporting global operations:
- 250+ data sources across retailer portals, 3rd party data providers, social media and marketing channels, warehouses, and manufacturing plants.
- Diverse data formats: Oracle and Azure SQL databases, flat files, SFTPs, direct emails, and third-party APIs
- Varied ingestion patterns: Different file formats (Excel, CSV, Parquet, JSON, Fixed-width files, etc.), hourly data feeds, CDC (Change Data Capture), and different load patterns (append, overwrite, merge, SCD2)
- Enterprise-scale processing: Managing data quality and consistency across multiple systems and geographies, tracking data lineage, and cataloguing all ingested data assets
Strategic Objectives
The data ingestion team identified key requirements for a modern ingestion framework:
- Scalability: Support rapid onboarding of new data sources without a proportional increase in engineering effort
- Maintainability: Reduce technical complexity through standardization and reusable patterns
- Observability: Provide comprehensive monitoring and data lineage tracking across all pipelines
- Agility: Enable faster time-to-value for analytics and operational use cases
The solution needed to support both the current data landscape and anticipated growth, while enabling self-service capabilities for analytics teams.
Solution Architecture: Metadata-Driven Framework on Databricks
Architectural Principles
The framework architecture is built on three foundational principles:
- Configuration over Code: Define ingestion logic through metadata rather than custom scripts
- Reusability: Build generic, parameterized pipelines that work for any source type
- Observability: Centralized monitoring, logging, and data lineage tracking
Architecture Overview
The framework implements a layered architecture (Landing → Raw → Curated) with event-driven orchestration using Databricks Lakeflow Jobs. The architecture consists of eight key stages working together seamlessly:
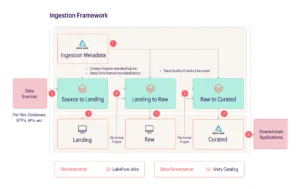
Stage 1: Ingestion Metadata (Delta Lake)
The central configuration store is implemented as Delta Lake tables, containing all metadata for data sources, column mappings, transformation rules, and load pattern specifications. This Delta Lake-based metadata repository enables version control, audit history, and ACID guarantees for configuration changes.
Configuration includes source identifiers, connection details (for flat files, databases, SFTPs, APIs), target storage paths, scheduling parameters, and load pattern types. The metadata drives all downstream processing stages through declarative configuration.
Stage 2: Source to Landing
Universal extraction logic that reads from diverse source types, including flat files, relational databases, SFTP servers, and REST APIs, and writes to the Azure data lake in as-is format. The process applies minimal transformation—primarily adding audit columns (ingestion timestamp and source file reference) before writing to the landing zone.
It also supports incremental loading through watermark tracking for databases, continuous streaming for real-time sources, and batch processing for file-based systems. All data is written to the Azure data lake in as-is format.
Stage 3: Landing Storage with File Arrival Trigger
The landing zone stores raw extracted data in as-is format. File arrival triggers automatically initiate the next stage (Landing to Raw) when new data lands, enabling event-driven processing without manual intervention or scheduled polling.
Stage 4: Landing to Raw Transformation
This stage applies metadata-driven standardization, including column header standardization (renaming based on metadata mappings), data type conversions to the target schema, transformation functions (string cleaning, numeric conversions, date parsing), and date/time format standardization across all sources.
The transformation logic is entirely driven by metadata configuration—the same notebook code processes every data source by reading and applying the appropriate transformation rules from the metadata repository.
Stage 5: Raw Storage with File Arrival Trigger
The raw layer contains standardized, cleaned data with consistent column naming and data types across all sources. File arrival triggers automatically cascade to the next processing stage (Raw to Curated), maintaining end-to-end event-driven flow.
Stage 6: Raw to Curated Transformation
This stage focuses on data quality validation and intelligent data loading. Comprehensive data quality checks are executed, combining both data validation and functional checks:
- Data validation checks: Null and duplicate validation for required fields, schema validation, uniqueness constraints for primary keys, and referential integrity verification across related tables
- Functional checks: Business rule validation, cross-field validation logic, data consistency checks, and threshold validations
Once data quality checks pass, data is loaded into Delta tables using the load pattern specified in the metadata configuration – Overwrite, Append, Merge, or SCD-2. The load pattern is declaratively configured in metadata, enabling consistent behaviour across all data sources without custom code.
Stage 7: Curated Storage (Delta Lake)
The curated layer contains quality-validated data loaded according to specified patterns, ready for downstream consumption. Tables are optimized with Z-ordering on frequently filtered columns and VACUUM operations to manage storage costs. Data retention policies are applied based on business requirements.
Stage 8: Downstream Applications
The curated data from the ingestion framework feeds into domain-oriented teams (domain pods) who are responsible for the next stage of data processing. These domain pods include:
- Commercial Domain: Harmonizes sales transactions data, customer interactions, and revenue operations
- Finance & Accounting Domain: Processes financial records, accounting data, and cost structures
- Operations Domain: Integrates operational metrics, inventory and resource management, and distribution data
- Planning Domain: Consolidates forecasting, strategic planning, and revenue projection signals
Each domain pod team takes the quality-validated, curated data and harmonizes it according to domain-oriented data models, applying business logic, transformations, and enrichments specific to their domain. This data is then loaded into the harmonized layer in Delta format.
This architecture maintains clear separation of concerns: the ingestion framework (Landing → Raw → Curated) focuses on data quality and load patterns, while domain pods (Curated → Silver) apply business context and domain logic.
Orchestration with Lakeflow Jobs
Databricks Lakeflow Jobs provides the orchestration layer with several advantages:
- Event-Driven Execution: File arrival triggers automatically initiate downstream processing, eliminating the need for scheduled polling and reducing latency
- Dependency Management: Jobs are sequenced based on data dependencies, with automatic handling of upstream completion
- Parallel Processing: Independent data sources are processed simultaneously, maximizing cluster utilization
- Built-in Retry Logic: Automatic retry with exponential backoff for transient failures
Governance with Unity Catalog
Unity Catalog provides enterprise-grade data governance:
- Centralized Access Control: Fine-grained permissions at catalog, schema, and table levels
- Data Lineage: Automatic tracking of data flow from source to consumption
- Audit Logging: Comprehensive logging of all data access and modifications
- Data Discovery: Searchable metadata and documentation for all datasets
- Data Sharing: Secure sharing capabilities across workspaces and organizations
Observability and Monitoring
The framework includes comprehensive monitoring across all layers:
Pipeline Execution Tracking
Every pipeline execution is tracked in a comprehensive auditing table that captures unique run identifiers, source identifiers, pipeline stage, start and end timestamps, execution status, record counts for both input and output, processing duration in seconds, and detailed error messages for failures. This granular tracking enables the team to quickly identify bottlenecks, investigate failures, and optimize pipeline performance.
Data Quality Metrics
Data quality validation results are stored in a dedicated metrics table containing the pipeline run identifier, source identifier, descriptive rule names, rule types, pass/fail status, count of records that failed validation, severity classification, and timestamp of validation. This historical tracking enables trend analysis to identify chronic data quality issues and supports root cause analysis when quality degrades.
Real-time Dashboards
Built using Databricks SQL dashboards showing:
- Pipeline success rates by source
- Data volume trends (daily, weekly, monthly)
- Number of data sources onboarded
- Ingestion coverage across regions and markets
- Ingestion distribution between DEV and PROD environments
Key Technical Decisions
Orchestration Platform Selection
The evaluation of orchestration platforms considered multiple options, including Apache Airflow, Azure Data Factory, and custom schedulers. Databricks Lakeflow Jobs was selected based on several technical and operational criteria:
- Platform Integration: Native execution on Databricks compute infrastructure eliminates cross-platform complexity and reduces operational overhead
- Event-Driven Architecture: File arrival triggers enable automatic cascade processing without scheduled polling, significantly reducing data processing latency
- Delta Lake Optimization: Built-in support for Delta Lake operations, including OPTIMIZE, Z-ORDER, and VACUUM commands, streamlines data management workflows
- Reliability: Configurable retry logic with exponential backoff patterns reduces manual intervention for transient failures
Delta Lake as the Storage Foundation
Delta Lake provides critical capabilities that enable the framework’s reliability and performance characteristics:
- ACID Transactions: Ensures data consistency through atomic operations, even during pipeline interruptions
- Time Travel: Enables point-in-time recovery and simplifies debugging through historical version access
- Schema Evolution: Supports automatic schema adaptation without pipeline reconfiguration
- Query Performance: OPTIMIZE and Z-ORDER operations significantly improve analytical query performance
Results and Business Impact
Quantitative Outcomes
Development Efficiency
- 80% reduction in time to onboard new data sources (from weeks to days)
- 90% reduction in code maintenance requirements
- 3x improvement in data ingestion team productivity
Operational Excellence
- 95-99% pipeline success rate for production workloads
- Zero-downtime deployments when adding new data sources
- 50% reduction in operational overhead
Scale and performance
- 250+ data sources across 20+ countries
- 5GB+ daily ingestion volume
- Sub-hour processing for most daily batches
Qualitative Outcomes
Self-Service Data Ingestion
The metadata-driven approach enables analytics engineers and data analysts to configure new data sources independently through metadata updates, reducing dependencies on the central ingestion team.
Standardized Data Quality
Centralized transformation logic ensures consistent data quality rules across all sources. The framework includes a library of reusable transformations—including date parsing, string cleaning, and deduplication—that can be applied declaratively via metadata configuration.
Enhanced Observability
The platform provides comprehensive visibility into data operations through centralized dashboards that track source-level ingestion status, pipeline execution trends, data volume patterns, and cost attribution across business units.
Future Roadmap
The ingestion team continues to enhance the framework with planned capabilities, including:
- Automated Metadata Creation: Leveraging LLMs to dynamically generate ingestion metadata for data sources by providing the required context.
- Automated Schema Detection: Dynamic schema inference and metadata updates to reduce manual configuration for schema changes
- Data Contract Integration: Integration with data contract frameworks to enforce service-level agreements for data quality
- Predictive Monitoring: Machine learning models for proactive pipeline failure prediction and automated remediation
Conclusion
The implementation of a metadata-driven ingestion framework on Databricks Lakeflow has transformed data operations for this global organization, delivering measurable improvements in efficiency, reliability, and cost optimization. The solution successfully addresses the challenges of managing enterprise-scale data integration while enabling self-service capabilities for analytical teams.
Key architectural insight: treating data pipelines as declarative configuration rather than imperative code enables unprecedented scalability and maintainability. This approach, combined with comprehensive metadata management and event-driven orchestration, creates a robust foundation for enterprise data operations.
The framework continues to evolve with new capabilities, source types, and enhanced monitoring features. The successful knowledge transfer and collaborative development approach has established a lasting organizational capability that extends beyond the original implementation scope.

Tapas Das
Data ArchitectTapas has close to a decade's experience in the data engineering field and has expertise in functions related to architecture design, business impact analysis, and much more. A deep-learning enthusiast, he is also making strides in the ML space, frequently cracking ML competitions and picking up titles such as MachineHack Grand Master and Kaggle Notebooks Expert. Beyond his work, he enjoys imparting his tech-knowhow by writing blogs and getting a chuckle out of fine DE-humour.


