Meet Sarah, CFO at a mid-sized retail enterprise. The night before a board meeting, she asks the company’s newly deployed AI analytics tool a straightforward question: “What is our net revenue for Q3?” The system responds instantly with a clean and confident number. Sarah builds her board presentation around it. The next morning, the Chief Revenue Officer flags an issue. The figure includes intercompany transactions that the finance team always excludes from official reporting. Sarah’s “net revenue” and the data team’s “net revenue” were never defined in the same way. But to the AI system, it was simply another field in the database. The instinct is to blame the AI. In reality, the system did exactly what it was built to do. It retrieved a value without understanding its business meaning. The problem was never the model itself. It was the absence of a business context.
Enterprise investment in conversational AI has grown significantly over the past few years. Across industries, organizations are deploying AI-powered assistants and analytics tools, expecting business users to query data, surface insights, and make real-time decisions without relying heavily on analysts or technical teams. Yet in many cases, those expectations remain unmet because enterprise data lacks the business context AI systems need to interpret it correctly.
Why Conversational AI Struggles with Business Context
Most enterprise data environments were built to store and process information, not to communicate meaning. A column named “rev” could refer to gross revenue, net revenue, revenue after returns, or something entirely specific to one region’s accounting practices. “Top customers” could be ranked by volume, margin, tenure, or strategic value depending on the team asking the question. Even a term like “active” may carry different definitions across business functions and reporting periods.
These distinctions rarely exist within the data itself. They live in the heads of analysts, in the footnotes of reports, in the institutional memory of teams who’ve been there long enough to know. When a conversational AI system is deployed on top of data that lacks this meaning, it cannot reliably resolve these ambiguities. It generates responses based on what it can interpret, which may be coherent and confident even when incorrect.
Why Metadata Alone Is Not Enough for Conversational AI
A recent industry report observed that as conversational analytics scales across enterprise functions, inconsistent metadata and fragmented business definitions increase the likelihood of misleading or conflicting outputs. As conversational analytics expands across functions, enterprises are realizing that governance alone is not enough. What they need is a way to systematically operationalize business meaning.
A common response to this challenge is to invest in metadata. Organizations add descriptions to data fields, build glossaries, and create tagging frameworks to improve governance and discoverability. These are important foundations for enterprise data management, but they are not yet sufficient to make conversational AI reliable.
Metadata provides static context. It tells the system what a field is called or what type of data it contains. But conversational AI requires a much deeper understanding of how information should be interpreted within the business. It needs to understand how definitions vary across functions, which business rules take precedence, and what a question actually means within a specific operational context.
Context Engineering: The Foundation of Reliable Enterprise AI
This is where conversational AI moves beyond metadata management into something far more operational: context engineering. Context engineering is the process of systematically embedding business meaning into AI systems in a structured, dynamic, and continuously maintained way.
It creates a semantic layer between enterprise data and business intent. This allows conversational AI systems to generate responses that align with organizational logic rather than simply retrieving information from underlying datasets.
In practice, context engineering includes:
- Mapping natural language queries to business logic
- Defining semantic relationships between metrics, KPIs, and datasets
- Encoding calculation rules, hierarchies, and business definitions
- Applying function-specific context to interpret the same query differently
- Continuously refining context as business logic evolves.
A recent report on ‘Databricks Genie’ noted that conversational analytics deployments depend heavily on semantic consistency, governance maturity, and clearly defined business definitions rather than simply exposing AI models to enterprise datasets.
At MathCo, this approach became foundational as we built AURA, a domain-driven analytics ecosystem developed on Databricks AI/BI Genie for a US-based global apparel retailer.
Instead of deploying a single generalized conversational layer across the Enterprise, AURA operationalized context engineering by creating dedicated intelligence spaces for functions such as Sales, Marketing, and Supply Chain, each built around its own business logic, semantic relationships, KPIs, and operational definitions. This meant that the same query could be interpreted differently depending on the functional context in which it was asked.
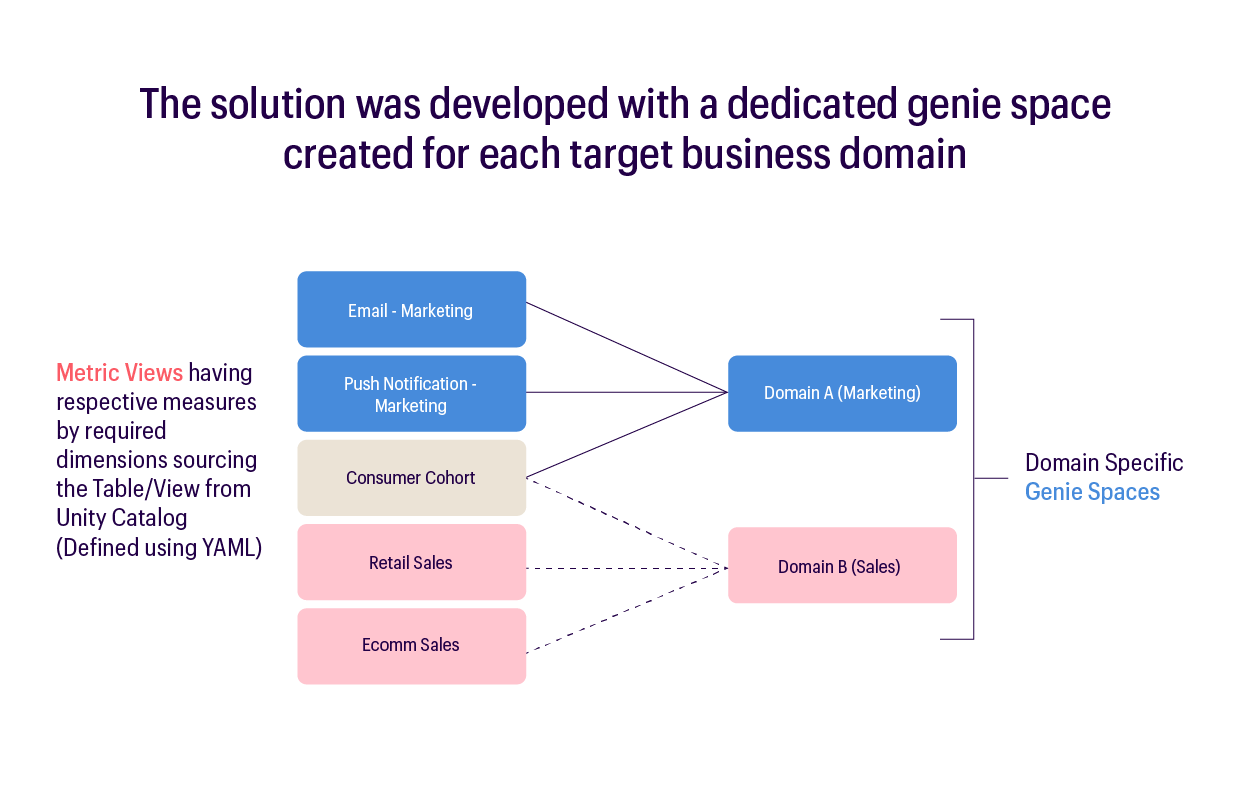
By embedding domain-specific business meaning directly into the conversational layer before enabling interactions, AURA improved query accuracy by approximately 30% during deployment while also accelerating the rollout of conversational analytics environments.
Beyond AURA, MathCo has enabled multiple organizations in the retail and consumer domain to operationalize Databricks for real-world decision intelligence use cases. The focus has consistently been on ensuring that conversational AI is not treated as a standalone interface, but as an embedded layer connected to governed data, business logic, and functional workflows.
This has translated into capabilities such as Conversational KPI Intelligence for natural-language exploration of business metrics and trends, Multi-Agent Decision Orchestration, where specialized agents work across sales, CRM, and analytics workflows, and Domain-Aware Insight Generation, which ensures every response is grounded in function-specific data models and business rules. These are further strengthened by real-time feedback loops for continuous learning, persistent conversation memory for iterative analysis, and no-code agent management that allows business teams to configure and scale intelligence layers without engineering overhead. Together, these capabilities help enterprises move from static dashboards to continuously adaptive, context-aware decision systems.
These capabilities reflect a broader shift in how enterprises must approach conversational AI. The real value lies not in the interface or models alone, but in how effectively the business context is structured and operationalized across systems.
Learn more about MathCo’s Databricks capabilities here.


MathCo’s Enterprise Launch Intelligence Capability for Scalable, Data-Driven Brand Execution
