There is a quiet crisis unfolding inside high-tech enterprises right now. It is not a shortage of data. If anything, the problem is the opposite. Organizations are drowning in it. Generative AI was expected to make insights instantly accessible, yet many teams still spend hours searching through dashboards, shared drives, and documentation portals to piece together answers. The problem becomes clear during everyday operational moments, like when a critical data pipeline fails just before an executive dashboard refresh. The answer usually exists somewhere in documentation, incident notes, or ticketing systems. The challenge is finding it quickly when it matters most.
This pattern plays out across the high-tech industry. Despite rapid progress in large language models, enterprises are discovering that the real bottleneck is not the model itself. It is how these systems retrieve the right information from the vast, fragmented knowledge inside the organization. Without a strong retrieval architecture connecting internal systems, history, and context, even the most powerful models struggle to produce useful answers. The effectiveness of AI depends less on the model and more on the retrieval layer that powers it.
Problems Start at the Source
Most high-tech enterprises experimenting with AI-powered knowledge systems eventually hit the same wall: the model produces answers that sound plausible but turn out to be wrong, incomplete, or outdated. When this happens, teams quickly revert to traditional ways of working, manually searching documents, validating information across systems, and relying on institutional memory. The result is predictable: stalled adoption, wasted time, duplicated effort, and a growing gap between the promise of AI and the reality on the ground. A major reason for this is that many implementations rely on what the industry calls Naive RAG, a simple pipeline that retrieves the closest text chunks from a vector database and passes them to a language model to generate an answer. It works in demos. It struggles in production.
In our experience working with leading high-tech organizations, the difference becomes clear very quickly. The teams that see real impact are not simply deploying generic RAG pipelines; they are deliberately architecting retrieval strategies that reflect how decisions are made, how knowledge is distributed, and how context evolves inside the enterprise. That shift often marks the difference between experimental AI systems and those ready for day-to-day operations.
Evolution of RAG as a Maturity Curve
RAG is often treated as a simple retrieval framework. In reality, it is better understood as a maturity curve, a progression of capabilities that evolves from basic information retrieval to systems that can reason over enterprise knowledge and trigger meaningful actions.
Early implementations focus primarily on improving retrieval accuracy, finding the most relevant pieces of information, and passing them to a model. As systems mature, they begin to incorporate richer context, relationships across data sources, orchestration across workflows, and eventually the ability to support decisions or trigger downstream actions.
The stages below describe this evolution as a practical maturity curve for enterprise AI systems. Each stage introduces a different level of complexity and is suited to different kinds of enterprise problems.
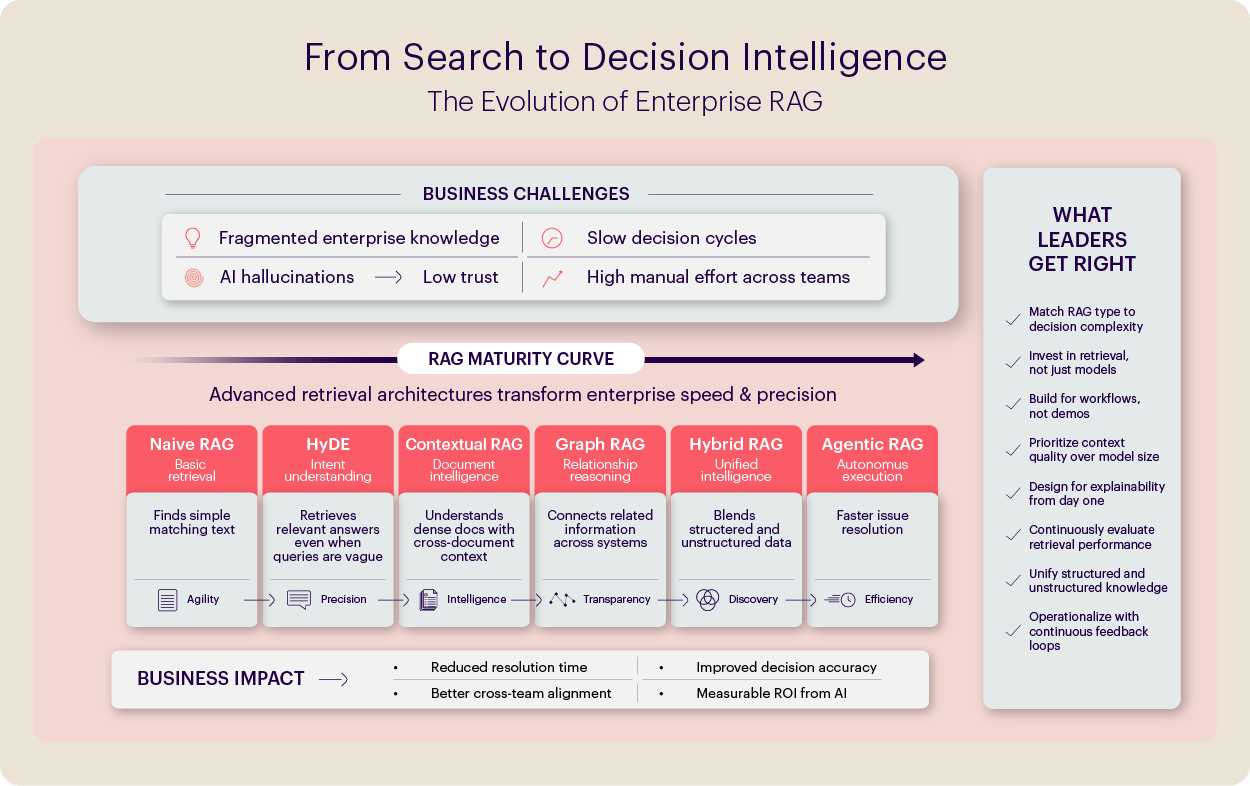
Stage 1: Getting Retrieval Right
Naive RAG: The Essential Foundation
For all its limitations in complex scenarios, Naive RAG is the right starting point for high-volume, well-defined knowledge retrieval. Think of a global enterprise software company where tier-1 support agents handle thousands of tickets daily. The questions are largely known, the answers exist in documentation, and the bottleneck is speed.
A well-implemented Naive RAG system gives support agents instant access to release notes, known issue logs, and configuration guides, dramatically reducing average handle time and improving first-contact resolution rates. For leaders, this is where the ROI case is easiest to build and fastest to prove.
HyDE – When Users Don’t Know What to Ask
Consider a pre-sales engineer who is preparing for a competitive displacement conversation. They don’t know exactly what to search for. They type: “How have we beaten Competitor X in deals involving enterprise security requirements?”
That query doesn’t match any document verbatim. Traditional retrieval fails.
Hypothetical Document Embedding (HyDE) solves this by generating a synthetic “ideal answer” to the query first, then using that to retrieve the most relevant real content. It bridges the gap between business language and technical documentation, making AI accessible not just to power users who know the right keywords, but to the sales rep, the account executive, and the demand generation team crafting messaging.
This works well when information can be retrieved in discrete chunks. But in reality, enterprise context is often spread across entire documents, with meaning emerging only when those pieces are brought together. This is where contextual intelligence becomes essential.
Stage 2: Contextual Intelligence
Contextual RAG: Mastering Long, Dense Documentation
At this stage, the challenge is no longer just retrieving the right text, it is understanding the context around it.
Consider this scenario, a product manager preparing for an enterprise renewal needs to confirm specific uptime guarantees and incident response commitments made to regulated customers. The information exists, but it is scattered across service-level agreements, compliance documentation, product architecture notes, and older contract templates. Retrieving a single paragraph from one document rarely provides the full answer because the meaning often depends on surrounding clauses, sections, and conditions.
Traditional retrieval systems break documents into small chunks and return the closest match. But enterprise knowledge rarely lives in sections, documents, and the structure around them. Contextual RAG addresses this by preserving that structure. Retrieved passages are enriched with document-level and section-level context so the model understands where the information came from and how it fits within the larger document. This significantly improves answer accuracy and reduces hallucinations when dealing with dense technical or contractual content.
However, when knowledge becomes more complex, spanning multiple entities and relationships, organizations begin moving toward approaches like Graph RAG, which helps AI reason across connected pieces of information rather than isolated text.
Graph RAG: System-Level Reasoning Across Relationships
This is where GenAI stops being a search engine and starts being an analyst. Consider a Director of Data Platforms trying to diagnose a recurring pipeline failure. The answer isn’t in any single document. It lives across the relationships between a microservice change log, a downstream dependency that was updated three weeks ago, a known issue filed by a different engineering team, and an SLA commitment that’s now at risk.
Graph RAG maps these relationships explicitly, building a knowledge graph (neo4j for example) that connects entities (products, services, teams, customers, contracts, incidents) and their interdependencies. Queries traverse this graph, enabling multi-hop reasoning that flat document retrieval simply cannot do.
In practice, enterprise problems rarely fit neatly into a single retrieval approach. This is where Hybrid RAG becomes critical, bridging structured data and unstructured knowledge to create a more complete and dependable intelligence layer for enterprise AI.
Hybrid RAG: Bridging Structured and Unstructured Intelligence
Hybrid RAG combines dense vector search (for unstructured content) with sparse keyword search and structured query capabilities (for databases and data warehouses) into a single retrieval layer. The result is an AI system that can answer questions like: “Which enterprise accounts using Feature X have had more than three critical support escalations in the last 90 days, and what were the common themes in those escalations?”
Such queries require unifying telemetry, support data, and qualitative insights from ticket transcripts. This level of synthesis is beyond any single retrieval method. And this is where the shift toward Agentic systems begins.
Stage 3: Enterprise Reasoning and Automation
Agentic RAG: From Answers to Action
Agentic RAG goes beyond simply retrieving information and generating responses. It introduces intelligent orchestration, where the system can dynamically determine how to solve a problem. Instead of relying on a single retrieval method, it can route queries to the most appropriate data sources, break complex questions into smaller sub-queries, retrieve information across multiple systems in parallel, and synthesize the results into a coherent response, often without the user even realizing the complexity behind the scenes.
At its most advanced, this evolves into agentic behavior. Here, AI systems are given a goal rather than a query. The agent plans a sequence of steps, retrieves the necessary knowledge, reasons through dependencies, and can trigger actions across systems to complete the task. In this model, AI moves beyond answering questions, it begins to actively participate in getting work done.
A Practical Enterprise Scenario
A support escalation manager at a high-tech company receives a critical ticket from a key enterprise customer reporting repeated failures after a recent release.
Step 1: Understanding the issue quickly
User Prompt: “Can you summarize what issues were reported after the latest release related to this module?”
The system pulls relevant release notes, known issues, and past tickets to summarize what might be causing the failure. (Naive RAG)
Step 2: Interpreting an unclear query
User Prompt: “Have we seen something like this before with similar customers?”
The system interprets the intent and surfaces related incidents and resolutions, even without exact keyword matches. (HyDE)
Step 3: Getting full context
User Prompt: “What commitments do we have for this customer if this issue continues?”
The system retrieves SLA commitments and contractual clauses, ensuring the issue is assessed in the right business context, not just technical isolation. (Contextual RAG)
Step 4: Identifying root cause patterns
User Prompt: “What changed recently that could be causing this?”
The system connects recent deployments, dependency changes, and past escalations across teams to identify the most likely root cause. (Graph RAG)
Step 5: Combining signals for decision-making
User Prompt: “Which other customers might be impacted by this issue?”
The system correlates telemetry data with support logs and customer feedback to highlight affected accounts and prioritize response. (Hybrid RAG)
Step 6: Moving to action
User Prompt: “Can you draft a summary and recommended next steps for the on-call team?”
The system generates a structured incident summary with recommended actions and shares it for immediate resolution. (Agentic RAG)
Notice how the prompts evolve from:
- specific → vague → contextual → diagnostic → strategic → action-oriented
This progression reinforces that RAG is not just retrieval, it is a spectrum of enterprise decision intelligence.
The MathCo Perspective
At MathCo, we go beyond implementing RAG pipelines, we engineer end-to-end retrieval architectures aligned to how decisions are actually made within the enterprise. From structuring fragmented knowledge systems and optimizing retrieval strategies to embedding governance, human oversight, and continuous evaluation, we build AI systems that are not just intelligent but dependable at scale.
Our work with global high-tech enterprises has shown that real impact comes from treating retrieval as a strategic capability. From enabling faster support resolution, improving pre-sales effectiveness, to powering decision-critical workflows, we design systems that translate AI potential into measurable business outcomes. We bring the full spectrum of capabilities needed to move organizations from experimentation to enterprise-grade intelligence.
Before scaling AI further, it is critical to ensure the foundation is built right. Let’s review your retrieval maturity and outline a practical path toward more accurate, dependable outcomes. Reach out to us at https:/mathco.com/contact-us/

